Testing Intel’s Arc A770 GPU for Deep Learning Pt. 1
Tutorial Links
- Getting Started with Intel’s PyTorch Extension for Arc GPUs on Ubuntu: This tutorial provides a step-by-step guide to setting up Intel’s PyTorch extension on Ubuntu to train models with Arc GPUs
- Getting Started with Intel’s PyTorch Extension for Arc GPUs on Windows: This tutorial provides a step-by-step guide to setting up Intel’s PyTorch extension on Windows to train models with Arc GPUs.
Overview
Last week, I received an Arc A770 GPU from Intel as part of their Graphics Innovator program. I am primarily interested in the card for its deep-learning performance, so I tested it with some of my tutorial projects and attempted to train some models using the pytorch-directml package.
Desktop Specs:
| OS | CPU | Memory | GPU Driver |
|---|---|---|---|
| Windows 10 Pro 21H2 | i7-11700K | 32 GB DDR4 3000MHz | 31.0.101.3490 |
Library Versions:
| OpenVINO | ONNX-DirectML | pytorch-directml |
|---|---|---|
| 2022.1 and 2022.2 | 1.12.1 | 1.8.0a0.dev220506 |
OpenVINO Inference
I first tested the card’s performance in the Unity project from my End-to-End Object Detection for Unity With IceVision and OpenVINO tutorial. The project uses OpenVINO 2022.1, and I noticed an odd sensitivity to input resolution when using FP16 precision.
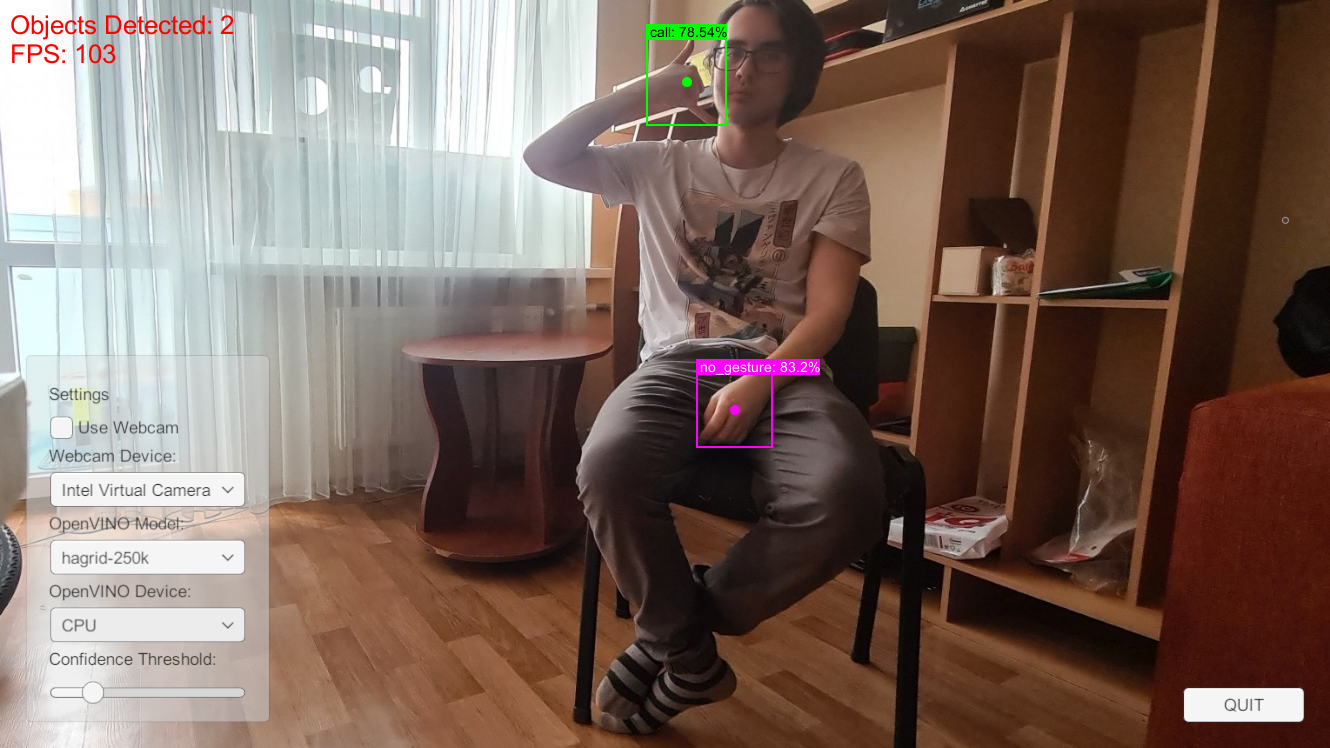
I use a default resolution of 398x224 (for a 16:9 aspect ratio), which translates to a 384x224 (divisible by 32) input resolution for the YOLOX tiny model. At this resolution, the model detects the same hand gestures with the Arc card as the CPU. However, the confidence scores are much lower, and the bounding box dimensions are slightly different (but still usable).
CPU (FP16)
- Objects Detected: Call 78.54%, No Gesture 83.2%
A770 (FP16)
- Objects Detected: Call 23.25%, No Gesture 40.86%

Moving to a higher resolution brought inconsistent improvements in accuracy and occasional crashes. The below sample is with an input resolution of 896x512 at FP16 precision.
Objects Detected: Call 78.06%

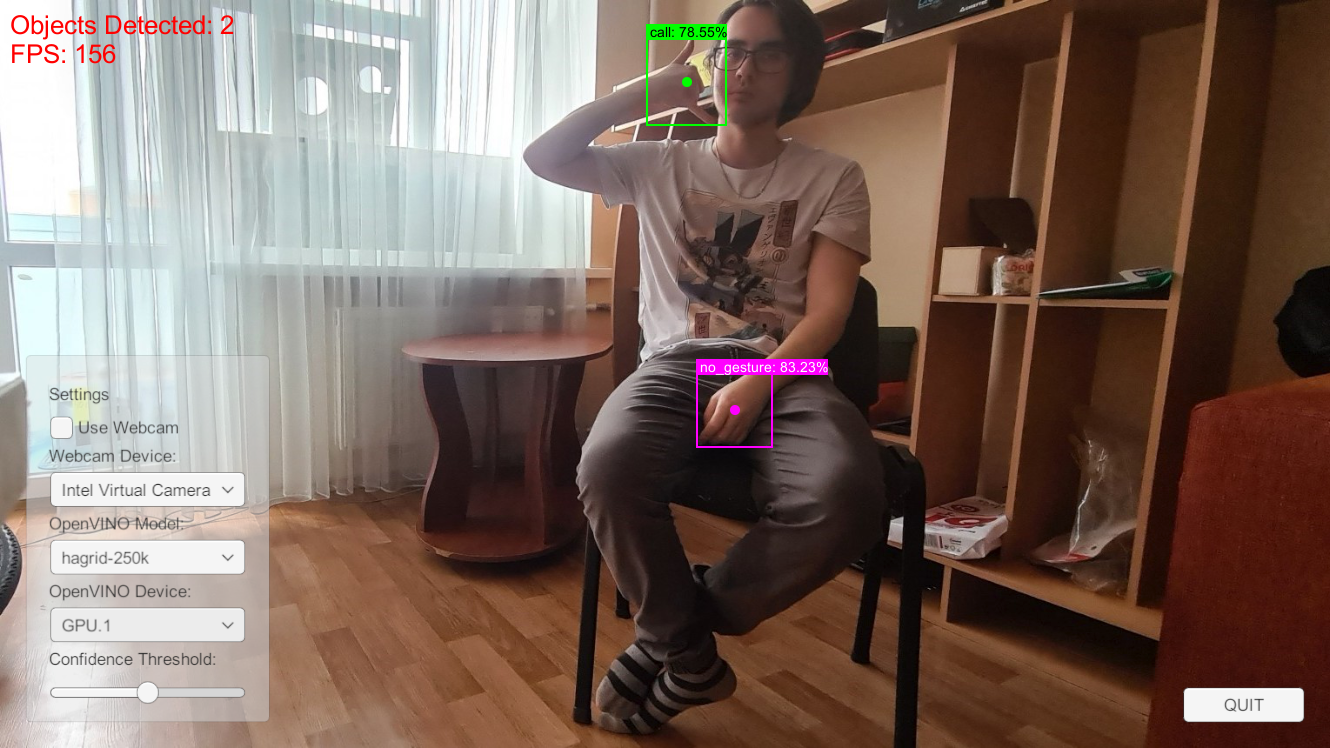
I later updated OpenVINO to the recent 2022.2 release, which resolved this issue.
Objects Detected: Call 78.55%, No Gesture 83.23%
ONNX-DirectML Inference
I used the project from my Object Detection for Unity With ONNX Runtime and DirectML tutorial to compare the inference speeds between the A770 and my Titan RTX. This project uses the same YOLOX tiny model and input resolution as the OpenVINO one but in FP32 precision.
The Titan RTX, essentially a 2080 Ti, hit around 145fps, while the A770 hovered around 120fps.
A770
Objects Detected: Call 78.64%, No Gesture 83.35%

PyTorch-DirectML Training
As far as I know, the only way to train models at the time of writing on an Arc card is with the pytorch-directml package (or tensorflow-directml package).
To test this, I set up a conda environment in WSL with the pytorch-directml package and downloaded the sample repo provided by Microsoft. The pytorch-directml package requires python 3.8, and the sample repo uses torchvision 0.9.0.
I successfully trained a ResNet50 model on CIFAR-10 with the sample training script. GPU memory usage was volatile when using a batch size higher than 4. The ResNet50 training script used less than 3.6 GB of GPU memory at a batch size of 4.
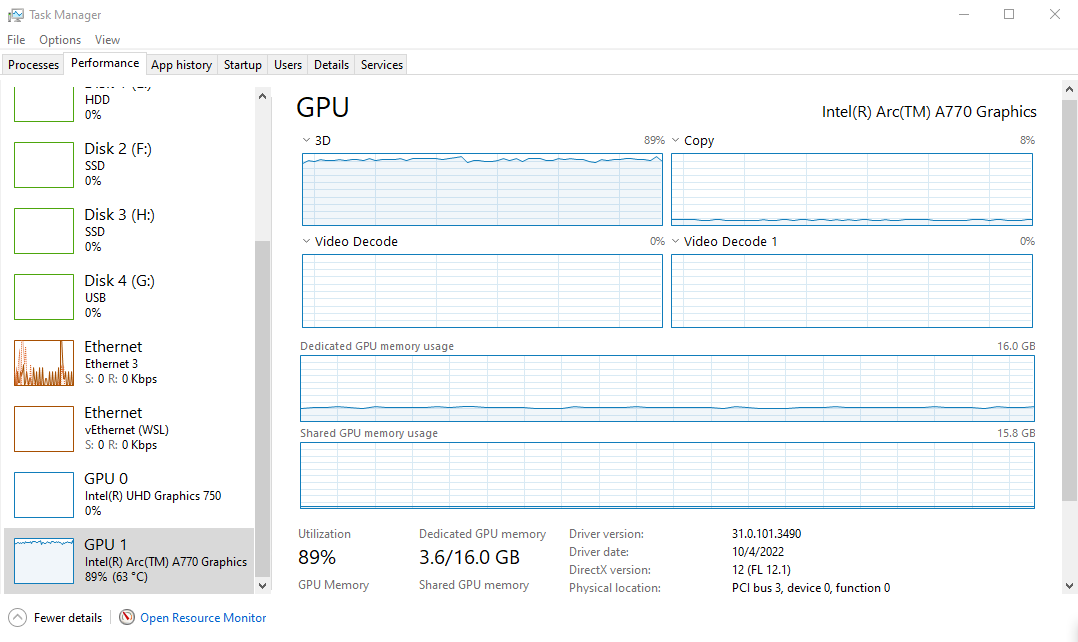
However, it spikes to using all 16 GB at a batch size of 8 and crashes the script. I was able to train at a batch size of 6, but barely.
I then attempted to train the style transfer model included with the pytorch examples repo and hit the wall of unimplemented operators. Here is the PyTorch DirectML Operator Roadmap. Some of the missing operators are on the current roadmap, but not all of them.
The tensorflow-directml package recently received its first update since May, so hopefully, the PyTorch version will receive an update soon. I have no idea when the main PyTorch and TensorFlow libraries will gain support for Intel GPUs, but hopefully, that is not too far off either.
I’m Christian Mills, an Applied AI Consultant and Educator.
Whether I’m writing an in-depth tutorial or sharing detailed notes, my goal is the same: to bring clarity to complex topics and find practical, valuable insights.
If you need a strategic partner who brings this level of depth and systematic thinking to your AI project, I’m here to help. Let’s talk about de-risking your roadmap and building a real-world solution.
Start the conversation with my Quick AI Project Assessment or learn more about my approach.