Getting Started with Intel’s PyTorch Extension for Arc GPUs on Windows
- Introduction
- Enable Resizable BAR in BIOS
- Install Drivers
- Install Microsoft Visual C++ Redistributable
- Disable Integrated Graphics
- Set Up a Python Environment
- Modify PyTorch Code
- Conclusion
Introduction
In this tutorial, I’ll guide you through setting up Intel’s PyTorch extension on Windows to train models with their Arc GPUs. The extension provides Intel’s latest feature optimizations and hardware support before they get added to PyTorch. Most importantly for our case, it includes support for Intel’s Arc GPUs and optimizations to take advantage of their Xe Matrix Extensions (XMX).
The XMX engines are dedicated hardware for performing matrix operations like those in deep-learning workloads. Intel’s PyTorch extension allows us to leverage this hardware with minimal changes to existing PyTorch code.
To illustrate this, we’ll adapt the training code from my beginner-level PyTorch tutorial, where we fine-tune an image classification model from the timm library for hand gesture recognition. By the end of this tutorial, you’ll know all steps required to set up Windows for training PyTorch models using Arc GPUs.
The current setup process is for version 2.3.110+xpu of Intel’s PyTorch extension.
To use the extension in WSL (Windows Subsystem for Linux), follow the Ubuntu version of this tutorial starting from the section linked below after enabling Resizable BAR:
Follow the steps in the linked section below to deactivate the Integrated Graphics. This step is still required to use the extension in WSL.
Enable Resizable BAR in BIOS
If you have an Arc GPU, one of the first things you should do is enable Resizable BAR. Resizable BAR allows a computer’s processor to access the graphics card’s entire memory instead of in small chunks. The Arc GPUs currently require this feature to perform as intended. You can enable the feature in your motherboard’s BIOS.
Here are links on how to do this for some of the popular motherboard manufacturers:
With Resizable BAR enabled, let’s ensure we have the latest drivers for our Arc GPU.
Install Drivers
We can download the latest Arc GPU drivers from Intel’s website at the link below:
The latest driver version available was 32.0.101.6078 at the time of writing. Click the Download button under Available Downloads to download the installer.
Once downloaded, double-click the installer executable and follow the prompts to install the drivers.
You don’t need to agree to join the Intel Computing Improvement program to install the drivers.
Once the installation completes, click the Reboot Recommended button to reboot the computer.
We can continue with the next step once we’re back in Windows.
Install Microsoft Visual C++ Redistributable
Intel’s documentation also lists the Microsoft Visual C++ Redistributable as a dependency for this extension version, so make sure to install it as well. You can download the latest version at the link below:
Disable Integrated Graphics
I encountered the following error when I attempted to use this version of Intel’s PyTorch extension on Windows:
RuntimeError: Can't add devices across platforms to a single context. -33 (PI_ERROR_INVALID_DEVICE)I could only resolve the issue by deactivating the iGPU in the Windows Device Manager. Future versions of the extension may eliminate this bug, but I’ll include the steps to turn off the iGPU for now.
Type Device Manager into the Windows search bar and click Open.
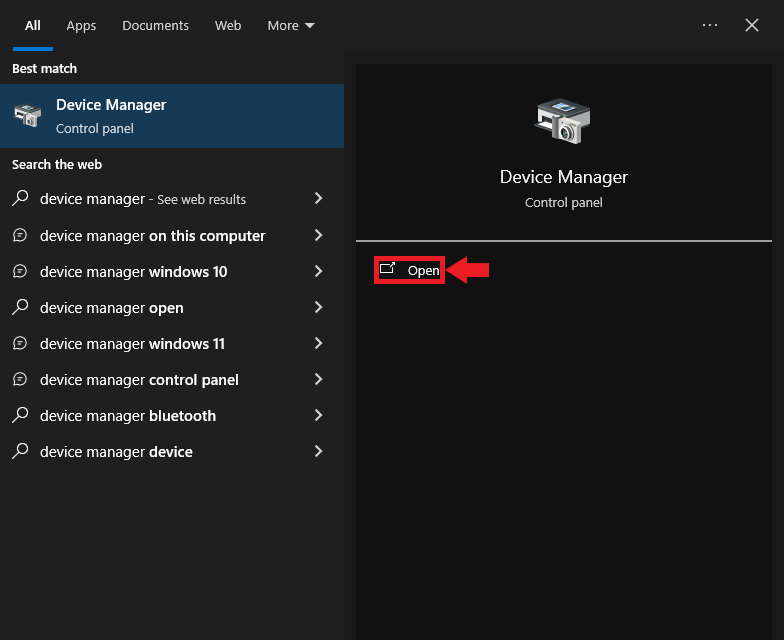
You will see the following popup message if you are not using an Administrator account. Click OK to continue.
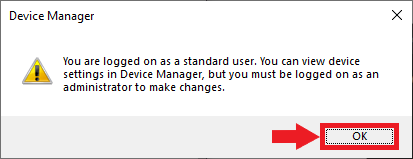
In the Device Manager window, open the Display adapters dropdown. There should be at least two options: the Arc GPU and the iGPU included with the CPU. Double-click the iGPU listing to open its properties window.
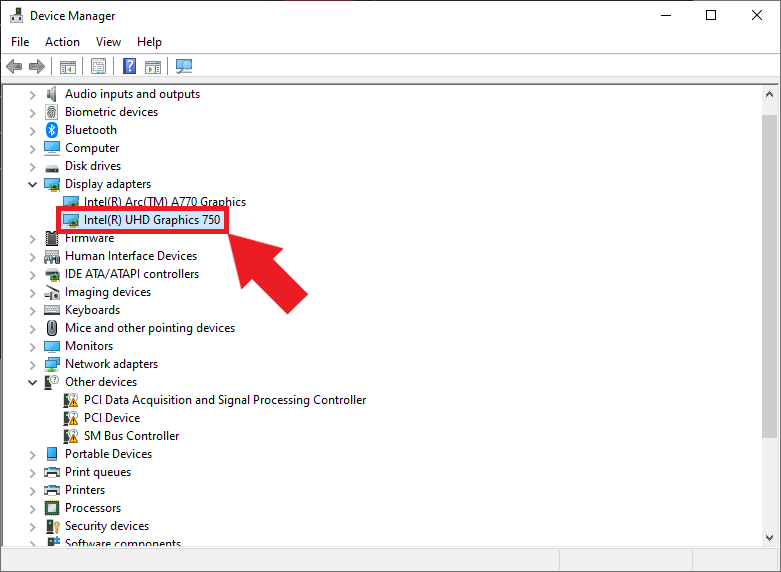
Non-Administrator users must click the Change settings button to enable changes to the iGPU device properties.
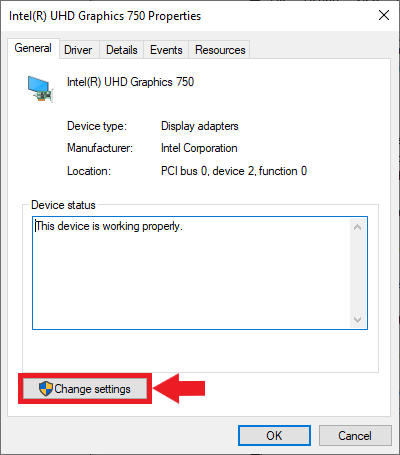
Next, select the Driver tab and click the Disable Device button.
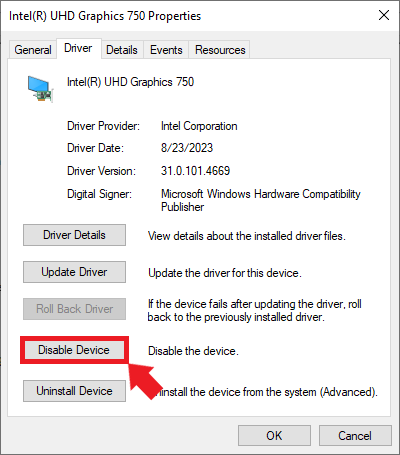
Click Yes in the popup window to confirm the changes.
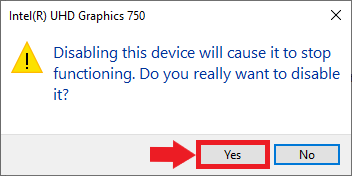
You will need to repeat this step when you install new graphics drivers in the future, assuming future releases of Intel’s extension do not resolve the issue.
Set Up a Python Environment
Now, we can create a Python environment to run the training code. We’ll install a patched version of PyTorch needed for Intel’s extension, the extension itself, and the other dependencies for the training code.
Install Mamba Package Manager
We’ll use the Mamba package manager to create the Python environment. I have a dedicated tutorial for setting up Mamba on Windows:
Open a command prompt window with the mamba environment active and navigate to a folder to store the training notebooks. For convenience, here is the command to activate the mamba environment from any command prompt window:
%USERPROFILE%\mambaforge\Scripts\activateCreate a Python Environment
Next, we’ll create a Python environment and activate it. The current version of the extension supports Python 3.11, so we’ll use that.
mamba create --name pytorch-arc python=3.11 -y
mamba activate pytorch-arcInstall Prerequisite Packages
The package for Intel’s PyTorch extension requires the libuv conda package:
mamba install libuv -yInstall PyTorch and Intel’s PyTorch extension
The following command will install the patched version of PyTorch and the extension itself:
pip install torch==2.3.1+cxx11.abi torchvision==0.18.1+cxx11.abi torchaudio==2.3.1+cxx11.abi intel-extension-for-pytorch==2.3.110+xpu --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/Install Training Code Dependencies
After that, we’ll install the training code dependencies. You can learn about these dependencies (here).
pip install jupyter matplotlib pandas pillow timm torcheval torchtnt tqdm
pip install cjm_pandas_utils cjm_psl_utils cjm_pil_utils cjm_pytorch_utils cjm_torchvision_tfmsThe previous version of this tutorial set an environment variable for the oneDNN memory layout to improve training speed. The performance improvement from this step is no longer significant and even prevents successful training for other model types.
If you followed the previous version of this tutorial, run the following commands to deactivate this environment variable:
set IPEX_XPU_ONEDNN_LAYOUT=0
setx IPEX_XPU_ONEDNN_LAYOUT 0Modify PyTorch Code
It’s finally time to train a model. The Jupyter Notebooks with the original and modified training code are available on GitHub at the links below.
- notebooks/pytorch-timm-image-classifier-training-windows.ipynb
- notebooks/intel-arc-pytorch-timm-image-classifier-training-windows.ipynb
- notebooks/windows_utils.py
You can also download the notebooks to the current directory by running the following commands:
curl -o pytorch-timm-image-classifier-training-windows.ipynb https://github.com/cj-mills/pytorch-timm-gesture-recognition-tutorial-code/blob/main/notebooks/pytorch-timm-image-classifier-training-windows.ipynbcurl -o intel-arc-pytorch-timm-image-classifier-training-windows-without-hf-datasets.ipynb https://raw.githubusercontent.com/cj-mills/pytorch-timm-gesture-recognition-tutorial-code/main/notebooks/intel-arc-pytorch-timm-image-classifier-training-windows.ipynbcurl -o windows_utils.py https://github.com/cj-mills/pytorch-timm-gesture-recognition-tutorial-code/blob/main/notebooks/windows_utils.pyOnce downloaded, run the following command to launch the Jupyter Notebook Environment:
jupyter notebookImport PyTorch Extension
We import Intel’s PyTorch extension with the following code:
import torch
import intel_extension_for_pytorch as ipex
print(f'PyTorch Version: {torch.__version__}')
print(f'Intel PyTorch Extension Version: {ipex.__version__}')C:\Users\Personal\mambaforge\envs\pytorch-arc\Lib\site-packages\torchvision\io\image.py:13: UserWarning: Failed to load image Python extension: 'Could not find module 'C:\Users\Personal\mambaforge\envs\pytorch-arc\Lib\site-packages\torchvision\image.pyd' (or one of its dependencies). Try using the full path with constructor syntax.'If you don't plan on using image functionality from `torchvision.io`, you can ignore this warning. Otherwise, there might be something wrong with your environment. Did you have `libjpeg` or `libpng` installed before building `torchvision` from source?
warn(
PyTorch Version: 2.3.1+cxx11.abi
Intel PyTorch Extension Version: 2.3.110+xpu
C:\Users\Personal\mambaforge\envs\pytorch-arc\Lib\site-packages\intel_extension_for_pytorch\llm\__init__.py:9: UserWarning: failed to use huggingface generation fuctions due to: No module named 'transformers'.
warnings.warn(f"failed to use huggingface generation fuctions due to: {e}.")Update PyTorch Imports
We don’t want to re-import torch after the extension, so we’ll remove that line from the Import PyTorch dependencies section.
# Import PyTorch dependencies
import torch.nn as nn
from torch.amp import autocast
from torch.cuda.amp import GradScaler
from torch.utils.data import Dataset, DataLoader# Import PyTorch dependencies
import torch
import torch.nn as nn
from torch.amp import autocast
from torch.cuda.amp import GradScaler
from torch.utils.data import Dataset, DataLoaderVerify Arc GPU Availability
We can double-check that the extension can use the Arc GPU by getting the properties of the available xpu devices.
import pandas as pd
def get_public_properties(obj):
"""
Extract all public properties from an object.
Args:
obj: The object to extract properties from.
Returns:
dict: A dictionary containing the object's public properties and their values.
"""
return {
prop: getattr(obj, prop)
for prop in dir(obj)
if not prop.startswith("__") and not callable(getattr(obj, prop))
}
# Get the number of available XPU devices
xpu_device_count = torch.xpu.device_count()
# Create a list of dictionaries containing properties for each XPU device
dict_properties_list = [
get_public_properties(torch.xpu.get_device_properties(i))
for i in range(xpu_device_count)
]
# Convert the list of dictionaries to a pandas DataFrame for easy viewing
pd.DataFrame(dict_properties_list)| driver_version | gpu_eu_count | gpu_subslice_count | has_atomic64 | has_fp16 | has_fp64 | max_compute_units | max_num_sub_groups | max_work_group_size | name | platform_name | sub_group_sizes | total_memory | type | vendor | version | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.3.30714 | 512 | 64 | True | True | False | 512 | 128 | 1024 | Intel(R) Arc(TM) A770 Graphics | Intel(R) Level-Zero | [8, 16, 32] | 16704737280 | gpu | Intel(R) Corporation | 1.5 |
In this case, the A770 is the only device listed since we deactivated the integrated graphics on the CPU.
Update the Device Name
Next, we’ll manually set the device name to xpu.
device = 'xpu'
dtype = torch.float32
device, dtypedevice = get_torch_device()
dtype = torch.float32
device, dtypeOptimize the model and optimizer Objects
Before we run the train_loop function, we’ll use Intel’s PyTorch extension to apply optimizations to the model and optimizer objects. We’ll also cast the model to the bfloat16 data type, so we can train using mixed precision.
# Learning rate for the model
lr = 1e-3
# Number of training epochs
epochs = 3
# AdamW optimizer; includes weight decay for regularization
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, eps=1e-5)
# Optimize the model and optimizer objects
model, optimizer = ipex.optimize(model, optimizer=optimizer, dtype=torch.bfloat16)
# Learning rate scheduler; adjusts the learning rate during training
lr_scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer,
max_lr=lr,
total_steps=epochs*len(train_dataloader))
# Performance metric: Multiclass Accuracy
metric = MulticlassAccuracy()# Learning rate for the model
lr = 1e-3
# Number of training epochs
epochs = 3
# AdamW optimizer; includes weight decay for regularization
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, eps=1e-5)
# Learning rate scheduler; adjusts the learning rate during training
lr_scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer,
max_lr=lr,
total_steps=epochs*len(train_dataloader))
# Performance metric: Multiclass Accuracy
metric = MulticlassAccuracy()Train the Model
That’s it for the required changes to the training code. We can now run the train_loop function.
Epochs: 100% |█████████| 3/3 [24:21<00:00, 478.44s/it]
Train: 100% |█████████| 4324/4324 [07:56<00:00, 10.52it/s, accuracy=0.844, avg_loss=0.535, loss=0.572, lr=0.000994]
Eval: 100% |█████████| 481/481 [00:49<00:00, 28.10it/s, accuracy=0.95, avg_loss=0.162, loss=0.0692, lr=]
Train: 100% |█████████| 4324/4324 [07:41<00:00, 10.73it/s, accuracy=0.914, avg_loss=0.281, loss=0.412, lr=0.000462]
Eval: 100% |█████████| 481/481 [00:23<00:00, 28.84it/s, accuracy=0.979, avg_loss=0.0653, loss=0.0793, lr=]
Train: 100% |█████████| 4324/4324 [07:09<00:00, 11.16it/s, accuracy=0.96, avg_loss=0.124, loss=0.0497, lr=4.03e-9]
Eval: 100% |█████████| 481/481 [00:21<00:00, 29.63it/s, accuracy=0.99, avg_loss=0.0314, loss=0.0783, lr=]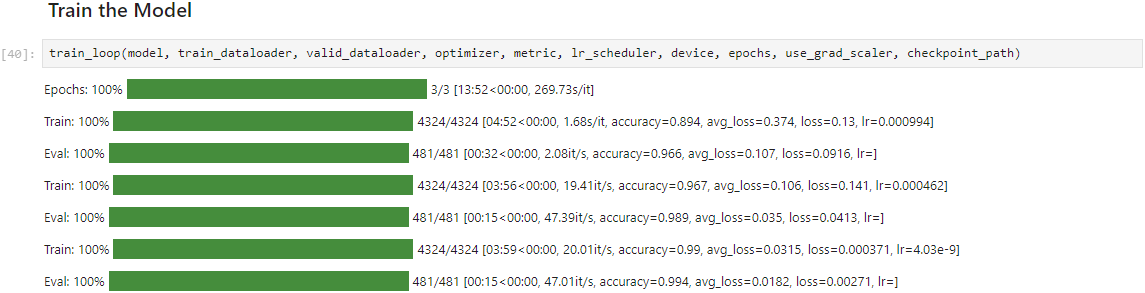
The training speed is significantly slower with this extension version. Although, it seems to improve with each iteration through the dataset.
Update the Inference Code
Since we cast the model to bloat16, we must ensure input data use the same type. We can update the inference code using the auto-cast context manager as shown below:
# Make a prediction with the model
with torch.no_grad(), autocast(torch.device(device).type):
pred = model(img_tensor)# Make a prediction with the model
with torch.no_grad():
pred = model(img_tensor)Conclusion
In this tutorial, we set up Intel’s PyTorch extension for the Windows OS and trained an image classification model using an Arc GPU. The exact setup steps may change with new versions, so check the documentation for the latest version to see if there are any changes. I’ll try to keep this tutorial updated with any significant changes to the process.
- Feel free to post questions or problems related to this tutorial in the comments below. I try to make time to address them on Thursdays and Fridays.
I’m Christian Mills, an Applied AI Consultant and Educator.
Whether I’m writing an in-depth tutorial or sharing detailed notes, my goal is the same: to bring clarity to complex topics and find practical, valuable insights.
If you need a strategic partner who brings this level of depth and systematic thinking to your AI project, I’m here to help. Let’s talk about de-risking your roadmap and building a real-world solution.
Start the conversation with my Quick AI Project Assessment or learn more about my approach.