Notes on Transformers Book Ch. 9
- Dealing with Few to No Labels
- Project: Build a GitHub Issues Tagger
- Implementing a Naive Bayesline
- Working with No Labeled Data
- Working with a Few Labels
- Leveraging Unlabeled Data
- Conclusion
- References
import transformers
import datasets
import accelerate
# Only print error messages
transformers.logging.set_verbosity_error()
datasets.logging.set_verbosity_error()
transformers.__version__, datasets.__version__, accelerate.__version__ ('4.18.0', '2.1.0', '0.5.1')import ast
# https://astor.readthedocs.io/en/latest/
import astor
import inspect
import textwrap
def print_source(obj, exclude_doc=True):
# Get source code
source = inspect.getsource(obj)
# Remove any common leading whitespace from every line
cleaned_source = textwrap.dedent(source)
# Parse the source into an AST node.
parsed = ast.parse(cleaned_source)
for node in ast.walk(parsed):
# Skip any nodes that are not class or function definitions
if not isinstance(node, (ast.FunctionDef, ast.ClassDef, ast.AsyncFunctionDef)):
continue
if exclude_doc and len(node.body) > 1: node.body = node.body[1:]
print(astor.to_source(parsed))Dealing with Few to No Labels
- We often have little to no labeled data when starting a new project.
- Non-pretrained models do not perform well with little data.
- Annotating additional training examples is time-consuming and expensive.
- There are several methods for dealing with few to no labels.
- Zero-shot learning often sets a strong baseline when there is no labeled data.
- Standard fine-tuning works well when there is a lot of labeled data.
- We can fine-tune a language model on a large corpus of unlabeled data before training a classifier on a small number of labeled examples.
- More sophisticated methods for training with unlabeled data include Unsupervised Data Augmentation and Uncertainty-aware self-training.
- We can use few-shot learning when we only have a small number of labeled examples and no unlabeled data.
- We can also use the embeddings from a pretrained language model to perform lookups with a nearest-neighbor search.
Project: Build a GitHub Issues Tagger
- Many support teams use issue trackers like Jira or GitHub to assist users by tagging issues with metadata based on the issue’s description.
- Tags can define the issue type, the product causing the problem, or which team is responsible for handling the reported issue.
- Automating issue tagging can significantly improve productivity and enables the support teams to focus on helping users.
- The goal is to train a model that automatically tags GitHub issues for the Hugging Face Transformers library.
- GitHub issues contain a title, a description, and a set of tags/labels that characterize them.
- The model will take a title and description as input and predict one or more labels (i.e., multilabel classification).
Getting the Data
- We can use the GitHub REST API to poll the Issues endpoint.
- The Issues endpoint returns a list of JSON objects.
- Each JSON object includes whether it is open or closed, who opened the issue, the title, the body, and the labels.
- The GitHub REST API treats pull requests as issues.
import time
import math
import requests
from pathlib import Path
import pandas as pd
from tqdm.auto import tqdmDefine a function to download issues for a GitHub project to a .jsonl file
- We need to download the issues in batches to avoid exceeding GitHub’s limit on the number of requests per hour.
def fetch_issues(owner="huggingface", repo="transformers", num_issues=10_000,
rate_limit=5_000):
batch = []
all_issues = []
# Max number of issues we can request per page
per_page = 100
# Number of requests we need to make
num_pages = math.ceil(num_issues / per_page)
base_url = "https://api.github.com/repos"
for page in tqdm(range(num_pages)):
# Query with state=all to get both open and closed issues
query = f"issues?page={page}&per_page={per_page}&state=all"
# Sample: https://api.github.com/repos/huggingface/transformers/issues?page=0&per_page=100&state=all
issues = requests.get(f"{base_url}/{owner}/{repo}/{query}")
batch.extend(issues.json())
if len(batch) > rate_limit and len(all_issues) < num_issues:
all_issues.extend(batch)
batch = [] # Flush batch for next time period
print(f"Reached GitHub rate limit. Sleeping for one hour ...")
time.sleep(60 * 60 + 1)
all_issues.extend(batch)
df = pd.DataFrame.from_records(all_issues)
df.to_json(f"github-issues-{repo}.jsonl", orient="records", lines=True)Note: It takes a while to fetch all the issues.
Download the GitHub Issues
# fetch_issues()Preparing the Data
import pandas as pd
pd.set_option('max_colwidth', None)
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.__version__ '1.4.2'Import the dataset
dataset_url = "https://git.io/nlp-with-transformers"
df_issues = pd.read_json(dataset_url, lines=True)
print(f"DataFrame shape: {df_issues.shape}")DataFrame shape: (9930, 26)Inspect a single GitHub issue
# Convert Series to DataFrame
df_issues.loc[2].to_frame()| 2 | |
|---|---|
| url | https://api.github.com/repos/huggingface/transformers/issues/11044 |
| repository_url | https://api.github.com/repos/huggingface/transformers |
| labels_url | https://api.github.com/repos/huggingface/transformers/issues/11044/labels{/name} |
| comments_url | https://api.github.com/repos/huggingface/transformers/issues/11044/comments |
| events_url | https://api.github.com/repos/huggingface/transformers/issues/11044/events |
| html_url | https://github.com/huggingface/transformers/issues/11044 |
| id | 849529761 |
| node_id | MDU6SXNzdWU4NDk1Mjk3NjE= |
| number | 11044 |
| title | [DeepSpeed] ZeRO stage 3 integration: getting started and issues |
| user | {‘login’: ‘stas00’, ‘id’: 10676103, ‘node_id’: ‘MDQ6VXNlcjEwNjc2MTAz’, ‘avatar_url’: ‘https://avatars.githubusercontent.com/u/10676103?v=4’, ‘gravatar_id’: ’‘, ’url’: ‘https://api.github.com/users/stas00’, ‘html_url’: ‘https://github.com/stas00’, ‘followers_url’: ‘https://api.github.com/users/stas00/followers’, ‘following_url’: ‘https://api.github.com/users/stas00/following{/other_user}’, ‘gists_url’: ‘https://api.github.com/users/stas00/gists{/gist_id}’, ‘starred_url’: ‘https://api.github.com/users/stas00/starred{/owner}{/repo}’, ‘subscriptions_url’: ‘https://api.github.com/users/stas00/subscriptions’, ‘organizations_url’: ‘https://api.github.com/users/stas00/orgs’, ‘repos_url’: ‘https://api.github.com/users/stas00/repos’, ‘events_url’: ‘https://api.github.com/users/stas00/events{/privacy}’, ‘received_events_url’: ‘https://api.github.com/users/stas00/received_events’, ‘type’: ‘User’, ‘site_admin’: False} |
| labels | [{‘id’: 2659267025, ‘node_id’: ‘MDU6TGFiZWwyNjU5MjY3MDI1’, ‘url’: ‘https://api.github.com/repos/huggingface/transformers/labels/DeepSpeed’, ‘name’: ‘DeepSpeed’, ‘color’: ‘4D34F7’, ‘default’: False, ‘description’: ’’}] |
| state | open |
| locked | False |
| assignee | {‘login’: ‘stas00’, ‘id’: 10676103, ‘node_id’: ‘MDQ6VXNlcjEwNjc2MTAz’, ‘avatar_url’: ‘https://avatars.githubusercontent.com/u/10676103?v=4’, ‘gravatar_id’: ’‘, ’url’: ‘https://api.github.com/users/stas00’, ‘html_url’: ‘https://github.com/stas00’, ‘followers_url’: ‘https://api.github.com/users/stas00/followers’, ‘following_url’: ‘https://api.github.com/users/stas00/following{/other_user}’, ‘gists_url’: ‘https://api.github.com/users/stas00/gists{/gist_id}’, ‘starred_url’: ‘https://api.github.com/users/stas00/starred{/owner}{/repo}’, ‘subscriptions_url’: ‘https://api.github.com/users/stas00/subscriptions’, ‘organizations_url’: ‘https://api.github.com/users/stas00/orgs’, ‘repos_url’: ‘https://api.github.com/users/stas00/repos’, ‘events_url’: ‘https://api.github.com/users/stas00/events{/privacy}’, ‘received_events_url’: ‘https://api.github.com/users/stas00/received_events’, ‘type’: ‘User’, ‘site_admin’: False} |
| assignees | [{‘login’: ‘stas00’, ‘id’: 10676103, ‘node_id’: ‘MDQ6VXNlcjEwNjc2MTAz’, ‘avatar_url’: ‘https://avatars.githubusercontent.com/u/10676103?v=4’, ‘gravatar_id’: ’‘, ’url’: ‘https://api.github.com/users/stas00’, ‘html_url’: ‘https://github.com/stas00’, ‘followers_url’: ‘https://api.github.com/users/stas00/followers’, ‘following_url’: ‘https://api.github.com/users/stas00/following{/other_user}’, ‘gists_url’: ‘https://api.github.com/users/stas00/gists{/gist_id}’, ‘starred_url’: ‘https://api.github.com/users/stas00/starred{/owner}{/repo}’, ‘subscriptions_url’: ‘https://api.github.com/users/stas00/subscriptions’, ‘organizations_url’: ‘https://api.github.com/users/stas00/orgs’, ‘repos_url’: ‘https://api.github.com/users/stas00/repos’, ‘events_url’: ‘https://api.github.com/users/stas00/events{/privacy}’, ‘received_events_url’: ‘https://api.github.com/users/stas00/received_events’, ‘type’: ‘User’, ‘site_admin’: False}] |
| milestone | NaN |
| comments | 0 |
| created_at | 2021-04-02 23:40:42 |
| updated_at | 2021-04-03 00:00:18 |
| closed_at | NaT |
| author_association | COLLABORATOR |
| active_lock_reason | None |
| body |
[This is not yet alive, preparing for the release, so please ignore for now]DeepSpeed ZeRO-3 has been integrated into HF transformers. I tried to write tests for a wide range of situations I’m sure I’ve missed some scenarios so if you run into any problems please file a separate issue. I’m going to use this issue to track progress on individual ZeRO3 issues.# Why would you want ZeRO-3a few words, while ZeRO-2 was very limited scability-wise - if model.half() couldn’t fit onto a single gpu, adding more gpus won’t have helped so if you had a 24GB GPU you couldn’t train a model larger than about 5B params.with ZeRO-3 the model weights are partitioned across multiple GPUs plus offloaded to CPU, the upper limit on model size has increased by about 2 orders of magnitude. That is ZeRO-3 allows you to scale to huge models with Trillions of parameters assuming you have enough GPUs and general RAM to support this. ZeRO-3 can benefit a lot from general RAM if you have it. If not that’s OK too. ZeRO-3 combines all your GPUs memory and general RAM into a vast pool of memory.you don’t have many GPUs but just a single one but have a lot of general RAM ZeRO-3 will allow you to fit larger models.course, if you run in an environment like the free google colab, while you can use run Deepspeed there, you get so little general RAM it’s very hard to make something out of nothing. Some users (or some sessions) one gets 12GB of RAM which is impossible to work with - you want at least 24GB instances. Setting is up might be tricky too, please see this notebook for an example:://github.com/stas00/porting/blob/master/transformers/deepspeed/DeepSpeed_on_colab_CLI.ipynb# Getting startedthe latest deepspeed version:\r\npip install deepspeed\r\nwill want to be on a transformers master branch, if you want to run a quick test:\r\ngit clone https://github.com/huggingface/transformers\r\ncd transformers\r\nBS=4; PYTHONPATH=src USE_TF=0 deepspeed examples/seq2seq/run_translation.py \\r\n--model_name_or_path t5-small --output_dir /tmp/zero3 --overwrite_output_dir --max_train_samples 64 \\r\n--max_val_samples 64 --max_source_length 128 --max_target_length 128 --val_max_target_length 128 \\r\n--do_train --num_train_epochs 1 --per_device_train_batch_size $BS --per_device_eval_batch_size $BS \\r\n--learning_rate 3e-3 --warmup_steps 500 --predict_with_generate --logging_steps 0 --save_steps 0 \\r\n--eval_steps 1 --group_by_length --adafactor --dataset_name wmt16 --dataset_config ro-en --source_lang en \\r\n--target_lang ro --source_prefix "translate English to Romanian: " \\r\n--deepspeed examples/tests/deepspeed/ds_config_zero3.json\r\nwill find a very detailed configuration here: https://huggingface.co/transformers/master/main_classes/trainer.html#deepspeednew config file will look like this:json\r\n{\r\n "fp16": {\r\n "enabled": true,\r\n "loss_scale": 0,\r\n "loss_scale_window": 1000,\r\n "initial_scale_power": 16,\r\n "hysteresis": 2,\r\n "min_loss_scale": 1\r\n },\r\n\r\n "zero_optimization": {\r\n "stage": 3,\r\n "cpu_offload": true,\r\n "cpu_offload_params": true,\r\n "cpu_offload_use_pin_memory" : true,\r\n "overlap_comm": true,\r\n "contiguous_gradients": true,\r\n "stage3_max_live_parameters": 1e9,\r\n "stage3_max_reuse_distance": 1e9,\r\n "stage3_prefetch_bucket_size": 0.94e6,\r\n "stage3_param_persistence_threshold": 1e4,\r\n "reduce_bucket_size": 1e6,\r\n "prefetch_bucket_size": 3e6,\r\n "sub_group_size": 1e14,\r\n "stage3_gather_fp16_weights_on_model_save": true\r\n },\r\n\r\n "optimizer": {\r\n "type": "AdamW",\r\n "params": {\r\n "lr": 3e-5,\r\n "betas": [0.8, 0.999],\r\n "eps": 1e-8,\r\n "weight_decay": 3e-7\r\n }\r\n },\r\n\r\n "scheduler": {\r\n "type": "WarmupLR",\r\n "params": {\r\n "warmup_min_lr": 0,\r\n "warmup_max_lr": 3e-5,\r\n "warmup_num_steps": 500\r\n }\r\n },\r\n\r\n "steps_per_print": 2000,\r\n "wall_clock_breakdown": false\r\n}\r\n\r\nif you were already using ZeRO-2 it’s only the zero_optimization stage that has changed.of the biggest nuances of ZeRO-3 is that the model weights aren’t inside model.state_dict, as they are spread out through multiple gpus. The Trainer has been modified to support this but you will notice a slow model saving - as it has to consolidate weights from all the gpus. I’m planning to do more performance improvements in the future PRs, but for now let’s focus on making things work.# Issues / Questionsyou have any general questions or something is unclear/missing in the docs please don’t hesitate to ask in this thread. But for any bugs or problems please open a new Issue and tag me there. You don’t need to tag anybody else. Thank you!
|
| performed_via_github_app | NaN |
| pull_request | None |
Note: The labels column contains the tags.
Inspect the labels column
pd.DataFrame(df_issues.loc[2]['labels'])| id | node_id | url | name | color | default | description | |
|---|---|---|---|---|---|---|---|
| 0 | 2659267025 | MDU6TGFiZWwyNjU5MjY3MDI1 | https://api.github.com/repos/huggingface/transformers/labels/DeepSpeed | DeepSpeed | 4D34F7 | False |
Extract the tags names from the labels column
df_issues["labels"] = (df_issues["labels"].apply(lambda x: [meta["name"] for meta in x]))df_issues[["labels"]].head()| labels | |
|---|---|
| 0 | [] |
| 1 | [] |
| 2 | [DeepSpeed] |
| 3 | [] |
| 4 | [] |
Get the number of labels per issue
df_issues["labels"].apply(lambda x : len(x)).value_counts().to_frame().T| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| labels | 6440 | 3057 | 305 | 100 | 25 | 3 |
Note: Most GitHub issues have zero or one label, and very few have more than one label.
View the only three issues with five tags
df_issues[df_issues['labels'].apply(lambda x: len(x) == 5)].T| 6005 | 7541 | 8266 | |
|---|---|---|---|
| url | https://api.github.com/repos/huggingface/transformers/issues/5057 | https://api.github.com/repos/huggingface/transformers/issues/3513 | https://api.github.com/repos/huggingface/transformers/issues/2787 |
| repository_url | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers |
| labels_url | https://api.github.com/repos/huggingface/transformers/issues/5057/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/3513/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/2787/labels{/name} |
| comments_url | https://api.github.com/repos/huggingface/transformers/issues/5057/comments | https://api.github.com/repos/huggingface/transformers/issues/3513/comments | https://api.github.com/repos/huggingface/transformers/issues/2787/comments |
| events_url | https://api.github.com/repos/huggingface/transformers/issues/5057/events | https://api.github.com/repos/huggingface/transformers/issues/3513/events | https://api.github.com/repos/huggingface/transformers/issues/2787/events |
| html_url | https://github.com/huggingface/transformers/issues/5057 | https://github.com/huggingface/transformers/issues/3513 | https://github.com/huggingface/transformers/issues/2787 |
| id | 639635502 | 589781536 | 562124488 |
| node_id | MDU6SXNzdWU2Mzk2MzU1MDI= | MDU6SXNzdWU1ODk3ODE1MzY= | MDU6SXNzdWU1NjIxMjQ0ODg= |
| number | 5057 | 3513 | 2787 |
| title | Examples tests improvements | Adding mbart-large-cc25 | Distillation code loss functions |
| user | {‘login’: ‘sshleifer’, ‘id’: 6045025, ‘node_id’: ‘MDQ6VXNlcjYwNDUwMjU=’, ‘avatar_url’: ‘https://avatars.githubusercontent.com/u/6045025?v=4’, ‘gravatar_id’: ’‘, ’url’: ‘https://api.github.com/users/sshleifer’, ‘html_url’: ‘https://github.com/sshleifer’, ‘followers_url’: ‘https://api.github.com/users/sshleifer/followers’, ‘following_url’: ‘https://api.github.com/users/sshleifer/following{/other_user}’, ‘gists_url’: ‘https://api.github.com/users/sshleifer/gists{/gist_id}’, ‘starred_url’: ‘https://api.github.com/users/sshleifer/starred{/owner}{/repo}’, ‘subscriptions_url’: ‘https://api.github.com/users/sshleifer/subscriptions’, ‘organizations_url’: ‘https://api.github.com/users/sshleifer/orgs’, ‘repos_url’: ‘https://api.github.com/users/sshleifer/repos’, ‘events_url’: ‘https://api.github.com/users/sshleifer/events{/privacy}’, ‘received_events_url’: ‘https://api.github.com/users/sshleifer/received_events’, ‘type’: ‘User’, ‘site_admin’: False} | {‘login’: ‘maksym-del’, ‘id’: 8141935, ‘node_id’: ‘MDQ6VXNlcjgxNDE5MzU=’, ‘avatar_url’: ‘https://avatars.githubusercontent.com/u/8141935?v=4’, ‘gravatar_id’: ’‘, ’url’: ‘https://api.github.com/users/maksym-del’, ‘html_url’: ‘https://github.com/maksym-del’, ‘followers_url’: ‘https://api.github.com/users/maksym-del/followers’, ‘following_url’: ‘https://api.github.com/users/maksym-del/following{/other_user}’, ‘gists_url’: ‘https://api.github.com/users/maksym-del/gists{/gist_id}’, ‘starred_url’: ‘https://api.github.com/users/maksym-del/starred{/owner}{/repo}’, ‘subscriptions_url’: ‘https://api.github.com/users/maksym-del/subscriptions’, ‘organizations_url’: ‘https://api.github.com/users/maksym-del/orgs’, ‘repos_url’: ‘https://api.github.com/users/maksym-del/repos’, ‘events_url’: ‘https://api.github.com/users/maksym-del/events{/privacy}’, ‘received_events_url’: ‘https://api.github.com/users/maksym-del/received_events’, ‘type’: ‘User’, ‘site_admin’: False} | {‘login’: ‘snaik2016’, ‘id’: 18183245, ‘node_id’: ‘MDQ6VXNlcjE4MTgzMjQ1’, ‘avatar_url’: ‘https://avatars.githubusercontent.com/u/18183245?v=4’, ‘gravatar_id’: ’‘, ’url’: ‘https://api.github.com/users/snaik2016’, ‘html_url’: ‘https://github.com/snaik2016’, ‘followers_url’: ‘https://api.github.com/users/snaik2016/followers’, ‘following_url’: ‘https://api.github.com/users/snaik2016/following{/other_user}’, ‘gists_url’: ‘https://api.github.com/users/snaik2016/gists{/gist_id}’, ‘starred_url’: ‘https://api.github.com/users/snaik2016/starred{/owner}{/repo}’, ‘subscriptions_url’: ‘https://api.github.com/users/snaik2016/subscriptions’, ‘organizations_url’: ‘https://api.github.com/users/snaik2016/orgs’, ‘repos_url’: ‘https://api.github.com/users/snaik2016/repos’, ‘events_url’: ‘https://api.github.com/users/snaik2016/events{/privacy}’, ‘received_events_url’: ‘https://api.github.com/users/snaik2016/received_events’, ‘type’: ‘User’, ‘site_admin’: False} |
| labels | [Examples, Good First Issue, Help wanted, cleanup, wontfix] | [Documentation, Help wanted, New model, seq2seq, translation] | [Core: Modeling, Distillation, PyTorch, Usage, wontfix] |
| state | closed | closed | closed |
| locked | False | False | False |
| assignee | {‘login’: ‘sshleifer’, ‘id’: 6045025, ‘node_id’: ‘MDQ6VXNlcjYwNDUwMjU=’, ‘avatar_url’: ‘https://avatars.githubusercontent.com/u/6045025?v=4’, ‘gravatar_id’: ’‘, ’url’: ‘https://api.github.com/users/sshleifer’, ‘html_url’: ‘https://github.com/sshleifer’, ‘followers_url’: ‘https://api.github.com/users/sshleifer/followers’, ‘following_url’: ‘https://api.github.com/users/sshleifer/following{/other_user}’, ‘gists_url’: ‘https://api.github.com/users/sshleifer/gists{/gist_id}’, ‘starred_url’: ‘https://api.github.com/users/sshleifer/starred{/owner}{/repo}’, ‘subscriptions_url’: ‘https://api.github.com/users/sshleifer/subscriptions’, ‘organizations_url’: ‘https://api.github.com/users/sshleifer/orgs’, ‘repos_url’: ‘https://api.github.com/users/sshleifer/repos’, ‘events_url’: ‘https://api.github.com/users/sshleifer/events{/privacy}’, ‘received_events_url’: ‘https://api.github.com/users/sshleifer/received_events’, ‘type’: ‘User’, ‘site_admin’: False} | {‘login’: ‘sshleifer’, ‘id’: 6045025, ‘node_id’: ‘MDQ6VXNlcjYwNDUwMjU=’, ‘avatar_url’: ‘https://avatars.githubusercontent.com/u/6045025?v=4’, ‘gravatar_id’: ’‘, ’url’: ‘https://api.github.com/users/sshleifer’, ‘html_url’: ‘https://github.com/sshleifer’, ‘followers_url’: ‘https://api.github.com/users/sshleifer/followers’, ‘following_url’: ‘https://api.github.com/users/sshleifer/following{/other_user}’, ‘gists_url’: ‘https://api.github.com/users/sshleifer/gists{/gist_id}’, ‘starred_url’: ‘https://api.github.com/users/sshleifer/starred{/owner}{/repo}’, ‘subscriptions_url’: ‘https://api.github.com/users/sshleifer/subscriptions’, ‘organizations_url’: ‘https://api.github.com/users/sshleifer/orgs’, ‘repos_url’: ‘https://api.github.com/users/sshleifer/repos’, ‘events_url’: ‘https://api.github.com/users/sshleifer/events{/privacy}’, ‘received_events_url’: ‘https://api.github.com/users/sshleifer/received_events’, ‘type’: ‘User’, ‘site_admin’: False} | None |
| assignees | [{‘login’: ‘sshleifer’, ‘id’: 6045025, ‘node_id’: ‘MDQ6VXNlcjYwNDUwMjU=’, ‘avatar_url’: ‘https://avatars.githubusercontent.com/u/6045025?v=4’, ‘gravatar_id’: ’‘, ’url’: ‘https://api.github.com/users/sshleifer’, ‘html_url’: ‘https://github.com/sshleifer’, ‘followers_url’: ‘https://api.github.com/users/sshleifer/followers’, ‘following_url’: ‘https://api.github.com/users/sshleifer/following{/other_user}’, ‘gists_url’: ‘https://api.github.com/users/sshleifer/gists{/gist_id}’, ‘starred_url’: ‘https://api.github.com/users/sshleifer/starred{/owner}{/repo}’, ‘subscriptions_url’: ‘https://api.github.com/users/sshleifer/subscriptions’, ‘organizations_url’: ‘https://api.github.com/users/sshleifer/orgs’, ‘repos_url’: ‘https://api.github.com/users/sshleifer/repos’, ‘events_url’: ‘https://api.github.com/users/sshleifer/events{/privacy}’, ‘received_events_url’: ‘https://api.github.com/users/sshleifer/received_events’, ‘type’: ‘User’, ‘site_admin’: False}] | [{‘login’: ‘sshleifer’, ‘id’: 6045025, ‘node_id’: ‘MDQ6VXNlcjYwNDUwMjU=’, ‘avatar_url’: ‘https://avatars.githubusercontent.com/u/6045025?v=4’, ‘gravatar_id’: ’‘, ’url’: ‘https://api.github.com/users/sshleifer’, ‘html_url’: ‘https://github.com/sshleifer’, ‘followers_url’: ‘https://api.github.com/users/sshleifer/followers’, ‘following_url’: ‘https://api.github.com/users/sshleifer/following{/other_user}’, ‘gists_url’: ‘https://api.github.com/users/sshleifer/gists{/gist_id}’, ‘starred_url’: ‘https://api.github.com/users/sshleifer/starred{/owner}{/repo}’, ‘subscriptions_url’: ‘https://api.github.com/users/sshleifer/subscriptions’, ‘organizations_url’: ‘https://api.github.com/users/sshleifer/orgs’, ‘repos_url’: ‘https://api.github.com/users/sshleifer/repos’, ‘events_url’: ‘https://api.github.com/users/sshleifer/events{/privacy}’, ‘received_events_url’: ‘https://api.github.com/users/sshleifer/received_events’, ‘type’: ‘User’, ‘site_admin’: False}] | [] |
| milestone | NaN | NaN | NaN |
| comments | 12 | 8 | 4 |
| created_at | 2020-06-16 12:45:32 | 2020-03-29 12:32:30 | 2020-02-09 05:21:33 |
| updated_at | 2020-10-04 01:14:08 | 2020-07-07 17:23:01 | 2020-04-19 22:29:10 |
| closed_at | 2020-10-04 01:14:08 | 2020-07-07 17:23:01 | 2020-04-19 22:29:10 |
| author_association | MEMBER | CONTRIBUTOR | NONE |
| active_lock_reason | None | None | None |
| body |
There are a few things about the examples/ tests that are suboptimal:. They never use cuda or fp16, even if they are available.. The @slow decorator used in the main tests is not importable, so there are no @slow tests.. test_run_glue uses distilbert-case-cased. It should use a smaller model, one of the tiny family here or a new tiny model.. There is no test coverage for TPU.help on any of these fronts would be much appreciated!
|
# 🌟 New model additionBART model implemented in fairseq introduced by FAIR## Model descriptionissue is to request adding mBART model existing as a part of fairseq lib. (https://github.com/pytorch/fairseq/tree/master/examples/mbart)(https://arxiv.org/abs/2001.08210)pretrained BART checkpoint.<!– Important information –>model code follows the original BART model code which is already a part of transformers repo. However, it introduces a couple more features like multilingual denoising and translation from pretrained BART. ## Open source status- [x] the model implementation is available: (give details)(https://github.com/pytorch/fairseq/commit/5e79322b3a4a9e9a11525377d3dda7ac520b921c) PR shows the main pieces that were added to the fairseq to make mBART work considering BART which is already existing in the codebase. However, a few additional mBART commits were added afterward.- [x] the model weights are available: (give details)(https://github.com/pytorch/fairseq/tree/master/examples/mbart#pre-trained-models)- [x] who are the authors: (mention them, if possible by @gh-username)AI Research (@MultiPath)
|
# ❓ Questions & Helpcompute cross entropy loss from the hard labels in distillation code?self.alpha_clm > 0.0:shift_logits = s_logits[…, :-1, :].contiguous()shift_labels = lm_labels[…, 1:].contiguous()loss_clm = self.lm_loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))loss += self.alpha_clm * loss_clmmodel outputs loss when passed with the labels.<!– The GitHub issue tracker is primarly intended for bugs, feature requests,new models and benchmarks, and migration questions. For all other questions,we direct you to Stack Overflow (SO) where a whole community of PyTorch andTensorflow enthusiast can help you out. Make sure to tag your question with theright deep learning framework as well as the huggingface-transformers tag: https://stackoverflow.com/questions/tagged/huggingface-transformers If your question wasn’t answered after a period of time on Stack Overflow, youcan always open a question on GitHub. You should then link to the SO question that you posted.–>## Details<!– Description of your issue –><!– You should first ask your question on SO, and only ifyou didn’t get an answer ask it here on GitHub. –>*A link to original question on Stack Overflow**: |
| performed_via_github_app | NaN | NaN | NaN |
| pull_request | None | None | None |
pandas.DataFrame.explode
- Documentation
- Transform each element of a list-like into a row, replicating index values.
Get the 20 most frequent labels in the dataset
df_counts = df_issues["labels"].explode().value_counts()
print(f"Number of labels: {len(df_counts)}")
# Display the top-20 label categories
df_counts.to_frame().head(20) Number of labels: 65| labels | |
|---|---|
| wontfix | 2284 |
| model card | 649 |
| Core: Tokenization | 106 |
| New model | 98 |
| Core: Modeling | 64 |
| Help wanted | 52 |
| Good First Issue | 50 |
| Usage | 46 |
| Core: Pipeline | 42 |
| Feature request | 41 |
| TensorFlow | 41 |
| Tests | 40 |
| PyTorch | 37 |
| DeepSpeed | 33 |
| seq2seq | 32 |
| Should Fix | 30 |
| marian | 29 |
| Discussion | 28 |
| Documentation | 28 |
| Examples | 24 |
df_counts[:2].sum() / df_counts.sum() 0.7185203331700147Note: * There are 65 unique tags (i.e., classes) in the dataset. * The dataset is highly imbalanced, with the two most common classes accounting for more than 70% of the dataset. * Some labels (e.g., “Good First” or “Help Wanted”) are potentially too difficult to predict from the issue’s description, while others (e.g., “model card”) might only require simple rules to classify.
Filter the dataset to a subset of labels
label_map = {"Core: Tokenization": "tokenization",
"New model": "new model",
"Core: Modeling": "model training",
"Usage": "usage",
"Core: Pipeline": "pipeline",
"TensorFlow": "tensorflow or tf",
"PyTorch": "pytorch",
"Examples": "examples",
"Documentation": "documentation"}
def filter_labels(x):
return [label_map[label] for label in x if label in label_map]
df_issues["labels"] = df_issues["labels"].apply(filter_labels)
all_labels = list(label_map.values())Check the distribution of the filtered dataset
df_counts = df_issues["labels"].explode().value_counts()
df_counts.to_frame().T| tokenization | new model | model training | usage | pipeline | tensorflow or tf | pytorch | documentation | examples | |
|---|---|---|---|---|---|---|---|---|---|
| labels | 106 | 98 | 64 | 46 | 42 | 41 | 37 | 28 | 24 |
df_counts[:2].sum() / df_counts.sum() 0.41975308641975306Note: The filtered dataset is more balanced, with the two most common classes accounting for less than 42% of the dataset.
Create a new column to indicate whether an issue is unlabeled
df_issues["split"] = "unlabeled"
mask = df_issues["labels"].apply(lambda x: len(x)) > 0
df_issues.loc[mask, "split"] = "labeled"
df_issues["split"].value_counts().to_frame()| split | |
|---|---|
| unlabeled | 9489 |
| labeled | 441 |
df_issues["split"].value_counts()[0] / len(df_issues) 0.9555891238670695Note: Over 95% of issues are unlabeled.
Inspect a labeled example
for column in ["title", "body", "labels"]:
print(f"{column}: {df_issues[column].iloc[26][:500]}\n") title: Add new CANINE model
body: # 🌟 New model addition
## Model description
Google recently proposed a new **C**haracter **A**rchitecture with **N**o tokenization **I**n **N**eural **E**ncoders architecture (CANINE). Not only the title is exciting:
> Pipelined NLP systems have largely been superseded by end-to-end neural modeling, yet nearly all commonly-used models still require an explicit tokenization step. While recent tokenization approaches based on data-derived subword lexicons are less brittle than manually en
labels: ['new model']Note: * This GitHub issue is proposing a new model architecture. * Both the title and description contain helpful information for the label classifier.
Concatenate the title and description for each issue into a new column
df_issues["text"] = (df_issues.apply(lambda x: x["title"] + "\n\n" + x["body"], axis=1))Remove any duplicate rows based on the text column values
len_before = len(df_issues)
df_issues = df_issues.drop_duplicates(subset="text")
print(f"Removed {(len_before-len(df_issues))/len_before:.2%} duplicates.") Removed 1.88% duplicates.import numpy as np
import matplotlib.pyplot as pltPlot the number of words per issue
(df_issues["text"].str.split().apply(len).hist(bins=np.linspace(0, 750, 50), grid=False, edgecolor="C0"))
plt.title("Words per issue")
plt.xlabel("Number of words")
plt.ylabel("Number of issues")
plt.show()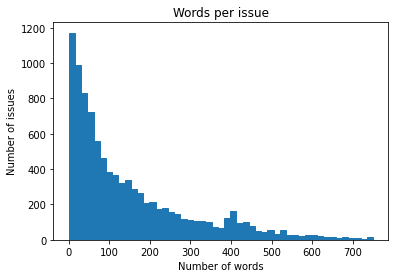
Note: * The text for most issues is short, but some have more than 500 words. * Issues with error messages and code snippets are often longer. * Most of the examples should fit into the typical context size of 512 tokens.
Creating Training Sets
- There is no guaranteed balance for all labels when splitting the dataset.
- We can use the scikit-multilearn library to approximate a balanced split.
scikit-multilearn library
- Homepage
- A multi-label classification library built on top of the scikit-learn ecosystem.
from sklearn.preprocessing import MultiLabelBinarizerMultiLabelBinarizer
- Documentation
- Transform between iterable of iterables and a multilabel format.
- Takes a list of names and creates a vector with zeros for absent labels and ones for present labels.
Create a MultiLabelBinarizer to learn the mapping from label to ID
mlb = MultiLabelBinarizer()
mlb.fit([all_labels]) MultiLabelBinarizer()Check the label mappings
mlb.transform([["tokenization", "new model"], ["pytorch"]]) array([[0, 0, 0, 1, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 1, 0, 0, 0]])pd.DataFrame(mlb.transform([[label] for label in all_labels]).T, columns=all_labels).T| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| tokenization | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| new model | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| model training | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| usage | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| pipeline | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| tensorflow or tf | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| pytorch | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| examples | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| documentation | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
from skmultilearn.model_selection import iterative_train_test_splititerative_train_test_split
Define a function to iteratively generate a balanced train/test split
def balanced_split(df, test_size=0.5):
ind = np.expand_dims(np.arange(len(df)), axis=1)
labels = mlb.transform(df["labels"])
ind_train, _, ind_test, _ = iterative_train_test_split(ind, labels,
test_size)
return df.iloc[ind_train[:, 0]], df.iloc[ind_test[:,0]]from sklearn.model_selection import train_test_splitSplit the data into supervised and unsupervised datasets
df_clean = df_issues[["text", "labels", "split"]].reset_index(drop=True).copy()
df_unsup = df_clean.loc[df_clean["split"] == "unlabeled", ["text", "labels"]]
df_sup = df_clean.loc[df_clean["split"] == "labeled", ["text", "labels"]]Create balanced training, validation, and test sets
np.random.seed(0)
df_train, df_tmp = balanced_split(df_sup, test_size=0.5)
df_valid, df_test = balanced_split(df_tmp, test_size=0.5)from datasets import Dataset, DatasetDictDataset.from_pandas
- Documentation
- Convert pandas.DataFrame to a pyarrow.Table to create a Dataset.
print_source(Dataset.from_pandas) @classmethod
def from_pandas(cls, df: pd.DataFrame, features: Optional[Features]=None,
info: Optional[DatasetInfo]=None, split: Optional[NamedSplit]=None,
preserve_index: Optional[bool]=None) ->'Dataset':
if info is not None and features is not None and info.features != features:
raise ValueError(
f"""Features specified in `features` and `info.features` can't be different:
{features}
{info.features}"""
)
features = (features if features is not None else info.features if info
is not None else None)
if info is None:
info = DatasetInfo()
info.features = features
table = InMemoryTable.from_pandas(df=df, preserve_index=preserve_index,
schema=features.arrow_schema if features is not None else None)
return cls(table, info=info, split=split)Initialize a DatasetDict with the dataset splits
ds = DatasetDict({
"train": Dataset.from_pandas(df_train.reset_index(drop=True)),
"valid": Dataset.from_pandas(df_valid.reset_index(drop=True)),
"test": Dataset.from_pandas(df_test.reset_index(drop=True)),
"unsup": Dataset.from_pandas(df_unsup.reset_index(drop=True))})
ds DatasetDict({
train: Dataset({
features: ['text', 'labels'],
num_rows: 223
})
valid: Dataset({
features: ['text', 'labels'],
num_rows: 106
})
test: Dataset({
features: ['text', 'labels'],
num_rows: 111
})
unsup: Dataset({
features: ['text', 'labels'],
num_rows: 9303
})
})Creating Training Slices
Create training slices with different numbers of samples
np.random.seed(0)
all_indices = np.expand_dims(list(range(len(ds["train"]))), axis=1)
indices_pool = all_indices
labels = mlb.transform(ds["train"]["labels"])
train_samples = [8, 16, 32, 64, 128]
train_slices, last_k = [], 0
for i, k in enumerate(train_samples):
# Split off samples necessary to fill the gap to the next split size
indices_pool, labels, new_slice, _ = iterative_train_test_split(
indices_pool, labels, (k-last_k)/len(labels))
last_k = k
if i==0: train_slices.append(new_slice)
else: train_slices.append(np.concatenate((train_slices[-1], new_slice)))
# Add full dataset as last slice
train_slices.append(all_indices), train_samples.append(len(ds["train"]))
train_slices = [np.squeeze(train_slice) for train_slice in train_slices]Note: It is not always possible to find a balanced split with a given split size.
print("Target split sizes:")
print(train_samples)
print("Actual split sizes:")
print([len(x) for x in train_slices]) Target split sizes:
[8, 16, 32, 64, 128, 223]
Actual split sizes:
[10, 19, 36, 68, 134, 223]Implementing a Naive Bayesline
- A baseline based on regular expressions, handcrafted rules, or a simple model might work well enough to solve a given problem.
- These are generally easier to deploy and maintain than transformer models.
- Baseline models provide quick sanity checks when exploring more complex models.
- A more complex model like BERT should perform better than a simple logistic regression classifier on the same dataset.
- A Naive Bayes Classifier is a great baseline model for text classification as it is simple, quick to train, and reasonably robust to changes in input.
Create a new ids column with the multilabel vectors for each training sample
def prepare_labels(batch):
batch["label_ids"] = mlb.transform(batch["labels"])
return batch
ds = ds.map(prepare_labels, batched=True)ds['train'][:5]['labels'], ds['train'][:5]['label_ids'] ([['new model'], ['new model'], ['new model'], ['new model'], ['examples']],
[[0, 0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0, 0, 0, 0]])from collections import defaultdictCreate dictionaries to store micro and macro \(F_{1}\)-scores
- The micro \(F_{1}\)-score tracks performance for on the frequent labels
- The macro \(F_{1}\)-score tracks performance on all the labels regardless of frequency
macro_scores, micro_scores = defaultdict(list), defaultdict(list)from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
from skmultilearn.problem_transform import BinaryRelevance
from sklearn.feature_extraction.text import CountVectorizersklearn.naive_bayes.MultinomialNB
- Documentation
- Create a Naive Bayes classifier for multinomial models.
sklearn.metrics._classification.classification_report
- Documentation
- Build a text report showing the main classification metrics.
skmultilearn.problem_transform.br.BinaryRelevance
- Documentation
- Treat each label as a separate single-class classification problem
sklearn.feature_extraction.text.CountVectorizer
- Documentation
- Create a vector where each entry corresponds to the frequency with which a token appeared in the text.
- Count vectorization is a bag-of-words approach since all information on the order of the words is lost.
# count_vect = CountVectorizer()
# pd.DataFrame(count_vect.fit_transform(ds['train'].select(train_slices[0])["text"]).toarray())Train a baseline Naive Bayes Classifier for each of the training slices
for train_slice in train_slices:
# Get training slice and test data
ds_train_sample = ds["train"].select(train_slice)
y_train = np.array(ds_train_sample["label_ids"])
y_test = np.array(ds["test"]["label_ids"])
# Use a simple count vectorizer to encode our texts as token counts
count_vect = CountVectorizer()
X_train_counts = count_vect.fit_transform(ds_train_sample["text"])
X_test_counts = count_vect.transform(ds["test"]["text"])
# Create and train our model!
classifier = BinaryRelevance(classifier=MultinomialNB())
classifier.fit(X_train_counts, y_train)
# Generate predictions and evaluate
y_pred_test = classifier.predict(X_test_counts)
clf_report = classification_report(
y_test, y_pred_test, target_names=mlb.classes_, zero_division=0,
output_dict=True)
# Store metrics
macro_scores["Naive Bayes"].append(clf_report["macro avg"]["f1-score"])
micro_scores["Naive Bayes"].append(clf_report["micro avg"]["f1-score"])Plot the performance of the baseline classifiers
def plot_metrics(micro_scores, macro_scores, sample_sizes, current_model):
fig, (ax0, ax1) = plt.subplots(1, 2, figsize=(10, 4), sharey=True)
for run in micro_scores.keys():
if run == current_model:
ax0.plot(sample_sizes, micro_scores[run], label=run, linewidth=2)
ax1.plot(sample_sizes, macro_scores[run], label=run, linewidth=2)
else:
ax0.plot(sample_sizes, micro_scores[run], label=run,
linestyle="dashed")
ax1.plot(sample_sizes, macro_scores[run], label=run,
linestyle="dashed")
ax0.set_title("Micro F1 scores")
ax1.set_title("Macro F1 scores")
ax0.set_ylabel("Test set F1 score")
ax0.legend(loc="lower right")
for ax in [ax0, ax1]:
ax.set_xlabel("Number of training samples")
ax.set_xscale("log")
ax.set_xticks(sample_sizes)
ax.set_xticklabels(sample_sizes)
ax.minorticks_off()
plt.tight_layout()
plt.show()plot_metrics(micro_scores, macro_scores, train_samples, "Naive Bayes")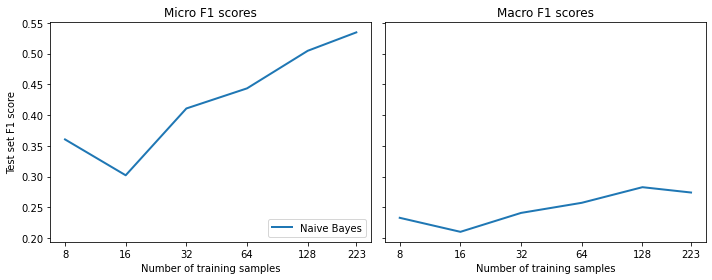
Note:
- The number of samples is on a logarithmic scale.
- The micro and macro F1 scores improve as the number of training samples increases.
- The results are slightly noisy since each slice can have a different class distribution.
Working with No Labeled Data
- Zero-shot classification is suitable when there is no labeled data at all.
- Zero-shot classification uses a pretrained model without additional fine-tuning on a task-specific corpus.
Zero-shot Fill-Mask Prediction
The pretrained model needs to be aware of the topic in the context to predict a missing token.
We can trick the model into classifying a document by providing a sentence like: > “This section was about the topic [MASK].”
The model should give a reasonable suggestion for the document’s topic.
Credit: Joe Davison
from transformers import pipelineCreate a Masked Language Modeling pipeline
pipe = pipeline("fill-mask", model="bert-base-uncased")
pipe, type(pipe.model), pipe.device (<transformers.pipelines.fill_mask.FillMaskPipeline at 0x7fd190bcd3a0>,
transformers.models.bert.modeling_bert.BertForMaskedLM,
device(type='cpu'))transformers.pipelines.fill_mask.FillMaskPipeline
- Documentation
- Create a masked language modeling prediction pipeline
Predict the topic for a movie about animals base on its description
movie_desc = "The main characters of the movie madacascar \
are a lion, a zebra, a giraffe, and a hippo. "
prompt = "The movie is about [MASK]."
output = pipe(movie_desc + prompt)
for element in output:
print(f"Token {element['token_str']}:\t{element['score']:.3f}%") Token animals: 0.103%
Token lions: 0.066%
Token birds: 0.025%
Token love: 0.015%
Token hunting: 0.013%Note: The model successfully performs zero-shot classification and only predicts tokens related to animals.
Check the probability that the movie description is about specific topics
output = pipe(movie_desc + prompt, targets=["animals", "cars"])
for element in output:
print(f"Token {element['token_str']}:\t{element['score']:.3f}%") Token animals: 0.103%
Token cars: 0.001%Note: The model is confident the movie is not about cars.
Predict the topic for a movie about cars based on its description
movie_desc = "In the movie transformers aliens \
can morph into a wide range of vehicles."
output = pipe(movie_desc + prompt)
for element in output:
print(f"Token {element['token_str']}:\t{element['score']:.3f}%") Token aliens: 0.221%
Token cars: 0.139%
Token robots: 0.099%
Token vehicles: 0.074%
Token transformers: 0.059%Check the probability that the movie description is about specific topics
movie_desc = "In the movie transformers aliens \
can morph into a wide range of vehicles."
output = pipe(movie_desc + prompt, targets=["animals", "cars"])
for element in output:
print(f"Token {element['token_str']}:\t{element['score']:.3f}%") Token cars: 0.139%
Token animals: 0.006%Text Entailment
- The model determines whether two text passages are likely to follow or contradict each other.
- A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference
- XNLI: Evaluating Cross-lingual Sentence Representations
- Typical datasets for text entailment tasks include the Multi-Genere NLI Corpus (MNLI) and the Cross-Lingual NLI Corpus (XNLI).
- Each sample in the dataset contains a premise, a hypothesis, and a label.
- The label can be either
entailment,neutral, orcontradiction.- The
entailmentlabel indicates the hypothesis text is necessarily correct under the premise. - The
contradictionlabel indicates the hypothesis is necessarily false or inappropriate under the premise. - The
neutrallabel indicates the hypothesis is unrelated to the premise.
- The
| Premise | Hypothesis | Label |
|---|---|---|
| His favorite color is blue. | He is into heavy metal | neutral |
| She finds the joke hilarious. | She thinkg the joke is not funny at all. | contradiction |
| The house was recently built. | The house is new. | entailment |
Zero-shot classification with Text Entailment
We can use a model trained on the MNLI dataset to build a classifier without needing any labels.
We treat the input text as a premise and formulate a hypothesis as: > “This example is about {label}.”
We insert the class name for the label.
The resulting entailment score indicates how likely the premise is about the topic.
We need to test different classes sequentially, meaning we need to execute a forward pass for each test.
The choice of label names can significantly impact prediction accuracy.
Choosing labels with a semantic meaning is generally the best approach.
from transformers import pipelineCreate a zero-shot classification pipeline
# Use GPU if available
pipe = pipeline("zero-shot-classification", device=0, fp16=True)
pipe, type(pipe.model), pipe.device(<transformers.pipelines.zero_shot_classification.ZeroShotClassificationPipeline at 0x7fd189242d00>, transformers.models.bart.modeling_bart.BartForSequenceClassification, device(type='cuda', index=0))Get the default hypothesis template
inspect.signature(pipe.preprocess).parameters['hypothesis_template'] <Parameter "hypothesis_template='This example is {}.'">transformers.pipelines.zero_shot_classification.ZeroShotClassificationPipeline
- Documentation
- Create a Natural-Language-Inference (NLI)-based zero-shot classification pipeline.
- The pipeline takes any combination of sequences and labels.
- The pipeline poses each combination as a premise-hypothesis pair and passes them to the pretrained model.
pd.Series(ds["train"][0]['text']).to_frame().style.hide(axis='columns').hide(axis='rows')len(ds["train"][0]['text'].split(' ')), len(pipe.tokenizer(ds["train"][0]['text'])['input_ids']) (244, 562)pd.DataFrame(ds["train"][0]['text'].split(' ')).T.style.hide(axis='columns')input_ids = pipe.tokenizer(ds["train"][0]['text'])['input_ids']
pd.DataFrame(pipe.tokenizer.convert_ids_to_tokens(input_ids)).T.style.hide(axis='columns')Test each possible label using text entailment
sample = ds["train"][0]
print(f"Labels: {sample['labels']}")
output = pipe(sample["text"], candidate_labels=all_labels, multi_label=True)
print(output["sequence"][:400])
print("\nPredictions:")
for label, score in zip(output["labels"], output["scores"]):
print(f"{label}, {score:.2f}") Labels: ['new model']
Add new CANINE model
# 🌟 New model addition
## Model description
Google recently proposed a new **C**haracter **A**rchitecture with **N**o tokenization **I**n **N**eural **E**ncoders architecture (CANINE). Not only the title is exciting:
> Pipelined NLP systems have largely been superseded by end-to-end neural modeling, yet nearly all commonly-used models still require an explicit tokeni
Predictions:
new model, 0.98
tensorflow or tf, 0.37
examples, 0.34
usage, 0.30
pytorch, 0.25
documentation, 0.25
model training, 0.24
tokenization, 0.17
pipeline, 0.16Note:
- The model is confident the text is about a new model, but it also produces relatively high scores for labels not found in the text.
- The highly technical domain of the text is very different from the original text distribution in the MNLI dataset.
- We can feed input with code to the model since we use a subword tokenizer.
- Tokenization might be inefficient with code since only a tiny fraction of the pretraining dataset contains code snippets.
- Code blocks can contain important information, such as frameworks used in the code.
Define a function to feed a single example through the zero-shot pipeline
def zero_shot_pipeline(example):
output = pipe(example["text"], all_labels, multi_label=True)
example["predicted_labels"] = output["labels"]
example["scores"] = output["scores"]
return exampleFeed the whole validation set through the pipeline
ds_zero_shot = ds["valid"].map(zero_shot_pipeline)Note: We can determine which labels to assign to each example using a minimum threshold value or selecting the top-k predictions.
Define a function to determine which set of labels to assign to each example using either a threshold value or top-k value
def get_preds(example, threshold=None, topk=None):
preds = []
if threshold:
for label, score in zip(example["predicted_labels"], example["scores"]):
if score >= threshold:
preds.append(label)
elif topk:
for i in range(topk):
preds.append(example["predicted_labels"][i])
else:
raise ValueError("Set either `threshold` or `topk`.")
return {"pred_label_ids": list(np.squeeze(mlb.transform([preds])))}Define a function that returns the scikit-learn classification report
def get_clf_report(ds):
y_true = np.array(ds["label_ids"])
y_pred = np.array(ds["pred_label_ids"])
return classification_report(
y_true, y_pred, target_names=mlb.classes_, zero_division=0,
output_dict=True)Test using top-k values to select labels
macros, micros = [], []
topks = [1, 2, 3, 4]
for topk in topks:
ds_zero_shot = ds_zero_shot.map(get_preds, batched=False,
fn_kwargs={'topk': topk})
clf_report = get_clf_report(ds_zero_shot)
micros.append(clf_report['micro avg']['f1-score'])
macros.append(clf_report['macro avg']['f1-score'])plt.plot(topks, micros, label='Micro F1')
plt.plot(topks, macros, label='Macro F1')
plt.xlabel("Top-k")
plt.ylabel("F1-score")
plt.legend(loc='best')
plt.show()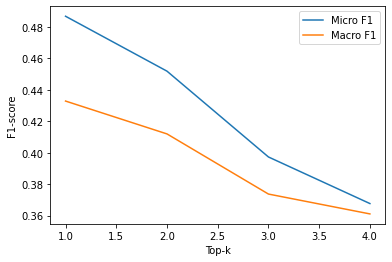
Note: We obtain the best results using only the highest score per example (i.e., top-1), given most examples only have one label.
Test using a threshold value to select labels
macros, micros = [], []
thresholds = np.linspace(0.01, 1, 100)
for threshold in thresholds:
ds_zero_shot = ds_zero_shot.map(get_preds,
fn_kwargs={"threshold": threshold})
clf_report = get_clf_report(ds_zero_shot)
micros.append(clf_report["micro avg"]["f1-score"])
macros.append(clf_report["macro avg"]["f1-score"])plt.plot(thresholds, micros, label="Micro F1")
plt.plot(thresholds, macros, label="Macro F1")
plt.xlabel("Threshold")
plt.ylabel("F1-score")
plt.legend(loc="best")
plt.show()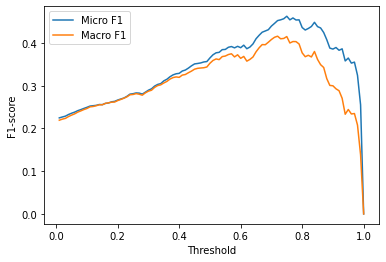
Note: The threshold approach performs slightly worse than the top-1 approach.
best_t, best_micro = thresholds[np.argmax(micros)], np.max(micros)
print(f'Best threshold (micro): {best_t} with F1-score {best_micro:.2f}.')
best_t, best_macro = thresholds[np.argmax(macros)], np.max(macros)
print(f'Best threshold (micro): {best_t} with F1-score {best_macro:.2f}.') Best threshold (micro): 0.75 with F1-score 0.46.
Best threshold (micro): 0.72 with F1-score 0.42.Note: A threshold value of around 0.8 provides the best tradeoff between precision and recall.
Compare the zero-shot classifier to the baseline Naive Bayes model
ds_zero_shot = ds['test'].map(zero_shot_pipeline)
ds_zero_shot = ds_zero_shot.map(get_preds, fn_kwargs={'topk': 1})
clf_report = get_clf_report(ds_zero_shot)
for train_slice in train_slices:
macro_scores['Zero Shot'].append(clf_report['macro avg']['f1-score'])
micro_scores['Zero Shot'].append(clf_report['micro avg']['f1-score'])plot_metrics(micro_scores, macro_scores, train_samples, "Zero Shot")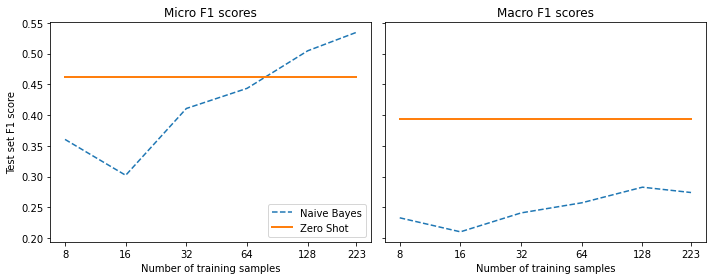
Note:
- The zero-shot pipeline outperforms the baseline when using less than 60 labeled examples universally outperforms the baseline when considering both micro and macro F1 scores.
- The baseline model performs better on the more common classes when using more than 60 examples.
- The zero-shot classification pipeline is sensitive to the names of labels and might perform better when using different or several names in parallel and aggregating them.
- Using a different
hypothesis_templatemight improve performance.
Working with a Few Labels
- There are often a few labeled examples available, at least, for most NLP projects.
- The labels might come directly from a client, a cross-company team, from hand annotating a few examples.
Data Augmentation
- We can use data augmentation to generate new training examples from existing ones. Perturbing words or characters can completely change the meaning. Noise introduced by data augmentation is less likely to change the meaning when the text is more than a few sentences.
Back Translation
- Back translation involves translating the original text into one or more target languages and translating it back to the source language.
- Back translation works best for high-resource languages or corpora that don’t contain too many domain-specific words.
- We can implement back translation models using machine translation models like MSM100.
Token Perturbations
- Token perturbations involve randomly choosing and performing simple transformations like synonym replacement, word insertion, swap, or deletion.
- Libraries like NlpAug and TextAttack provide various recipes for token perturbations.
- EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
| Augmentation | Sentence |
|---|---|
| None | Even if you defeat me Megatron, others will rise to defeat your tyranny |
| Synonym replace | Even if you kill me, Megatron, others will prove to defeat your tyranny |
| Random Insert | Even if you defeat me Megatron, others humanity will rise to defeat your tyranny |
| Random Swap | You even if defeat me Megatron, others will rise defeat to tyranny your |
| Random delete | Even if you me Megatron, others to defeat tyranny |
| Back translate (German) | Even if you defeat me, other will rise up to defeat your tyranny |
Disable Tokenizers Parallelism
%env TOKENIZERS_PARALLELISM=false env: TOKENIZERS_PARALLELISM=falsefrom transformers import set_seed
import nlpaug.augmenter.word as naw
import nlpaug.augmenter.char as nac
import nlpaug.augmenter.sentence as nas
import nlpaug.flow as nafc
import nltkDownload a perceptron model for tagging words and the Wordnet corpora
nltk.download('averaged_perceptron_tagger')
nltk.download('wordnet') Truenltk.download('omw-1.4') True!ls ~/nltk_data/corpora/wordnet adj.exc cntlist.rev data.noun index.adv index.verb noun.exc
adv.exc data.adj data.verb index.noun lexnames README
citation.bib data.adv index.adj index.sense LICENSE verb.exc!head -5 ~/nltk_data/corpora/wordnet/noun.exc aardwolves aardwolf
abaci abacus
aboideaux aboideau
aboiteaux aboiteau
abscissae abscissaReset random seed
set_seed(3)Define original text
text = "Even if you defeat me Megatron, others will rise to defeat your tyranny"Initialize augmentation dictionary
augs = {}nlpaug.augmenter.word.synonym.SynonymAug
- Documentation
- Create an augmenter that leverages semantic meaning to substitute words.
Add Synonym Replacement Augmentation using the WordNet corpora
augs["synonym_replace"] = naw.SynonymAug(aug_src='wordnet')
augs["synonym_replace"].augment(text) 'Even if you kill me Megatron, others will prove to defeat your tyranny'nlpaug.augmenter.word.context_word_embs.ContextualWordEmbsAug
- Documentation
- Create an augmenter that finds the top n similar words using contextual word embeddings
Add Random Insert Augmentation using the contextual word embeddings of DistilBERT
augs["random_insert"] = naw.ContextualWordEmbsAug(model_path="distilbert-base-uncased",
device="cpu", action="insert", aug_max=1)
augs["random_insert"].augment(text) 'even if you defeat me megatron, others humanity will rise to defeat your tyranny'nlpaug.augmenter.word.random.RandomWordAug
- Documentation
- Randomly apply substitute, swap, delete or crop augmentation
- The default augmentation is to delete words.
Randomly swap words
augs["random_swap"] = naw.RandomWordAug(action="swap")
augs["random_swap"].augment(text) 'You even if defeat me Megatron, others will rise defeat to tyranny your'Randomly delete words
augs["random_delete"] = naw.RandomWordAug()
augs["random_delete"].augment(text) 'Even if you me Megatron, others to defeat tyranny'nlpaug.augmenter.word.back_translation.BackTranslationAug
- Documentation
- Use two translation models to apply back translation
augs["bt_en_de"] = naw.BackTranslationAug(
from_model_name='facebook/wmt19-en-de',
to_model_name='facebook/wmt19-de-en'
)
augs["bt_en_de"].augment(text) 'Even if you defeat me, others will rise up to defeat your tyranny'for k,v in augs.items():
print(f"Original text: {text}")
print(f"{k}: {v.augment(text)}")
print("") Original text: Even if you defeat me Megatron, others will rise to defeat your tyranny
synonym_replace: Even if you defeat me Megatron, others will go up to vote out your tyranny
Original text: Even if you defeat me Megatron, others will rise to defeat your tyranny
random_insert: even if you defeat me megatron, others will rise to defeat of your tyranny
Original text: Even if you defeat me Megatron, others will rise to defeat your tyranny
random_swap: If even you defeat me Megatron, others will rise to defeat tyranny your
Original text: Even if you defeat me Megatron, others will rise to defeat your tyranny
random_delete: If you me Megatron, will to defeat your tyranny
Original text: Even if you defeat me Megatron, others will rise to defeat your tyranny
bt_en_de: Even if you defeat me, others will rise up to defeat your tyrannyReset random seed
set_seed(3)Add Random Synonym Replacement using the contextual word embeddings of DistilBERT
aug = naw.ContextualWordEmbsAug(model_path="distilbert-base-uncased",
device="cpu", action="substitute")
text = "Transformers are the most popular toys"
print(f"Original text: {text}")
print(f"Augmented text: {aug.augment(text)}") Original text: Transformers are the most popular toys
Augmented text: transformers'the most popular toysDefine a function to apply synonym replacement augmentation to a batch
def augment_text(batch, transformations_per_example=1):
text_aug, label_ids = [], []
for text, labels in zip(batch["text"], batch["label_ids"]):
text_aug += [text]
label_ids += [labels]
for _ in range(transformations_per_example):
text_aug += [aug.augment(text)]
label_ids += [labels]
return {"text": text_aug, "label_ids": label_ids}Train the baseline Naive Bayes Classifier using synonym replacement augmentation
for train_slice in train_slices:
# Get training slice and test data
ds_train_sample = ds["train"].select(train_slice)
# Flatten augmentations and align labels!
ds_train_aug = (ds_train_sample.map(
augment_text, batched=True, remove_columns=ds_train_sample.column_names)
.shuffle(seed=42))
y_train = np.array(ds_train_aug["label_ids"])
y_test = np.array(ds["test"]["label_ids"])
# Use a simple count vectorizer to encode our texts as token counts
count_vect = CountVectorizer()
X_train_counts = count_vect.fit_transform(ds_train_aug["text"])
X_test_counts = count_vect.transform(ds["test"]["text"])
# Create and train our model!
classifier = BinaryRelevance(classifier=MultinomialNB())
classifier.fit(X_train_counts, y_train)
# Generate predictions and evaluate
y_pred_test = classifier.predict(X_test_counts)
clf_report = classification_report(
y_test, y_pred_test, target_names=mlb.classes_, zero_division=0,
output_dict=True)
# Store metrics
macro_scores["Naive Bayes + Aug"].append(clf_report["macro avg"]["f1-score"])
micro_scores["Naive Bayes + Aug"].append(clf_report["micro avg"]["f1-score"])Compare the results
plot_metrics(micro_scores, macro_scores, train_samples, "Naive Bayes + Aug")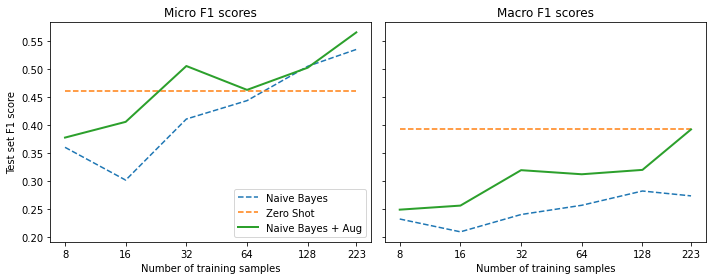
Note:
- A small amount of data augmentation improves the F1 score of the Naive Bayes Classifier.
- The Naive Bayes Classifier overtakes the zero-shot pipeline for the macro F1 score at around 220 training samples.
Using Embeddings as a Lookup Table
Large language models like GPT-3 are excellent at solving tasks with limited data because they learn representations of text that encode information across many dimensions.
We can use embeddings of large language models to develop a semantic search engine, find similar documents or comments, or classify text.
This approach does not require fine-tuning models to leverage the few labeled data points.
The embeddings should ideally be from a pretrained on a similar domain to the target dataset.
Steps to classify text using embeddings:
- Use the language model to embed all labeled texts.
- Perform a nearest-neighbor search over the stored embeddings.
- Aggregate the labels of the nearest neighbors to get a prediction.
- We need to embed new text we want to classify and assign labels based on the labels of its nearest neighbors.
- It is crucial to calibrate the number of neighbors for the nearest-neighbors search.
- Using too few neighbors might result in noisy predictions.
- Using too many neighbors might mix neighboring groups.
import torch
from transformers import AutoTokenizer, AutoModelInstantiate a tokenizer and model using a GPT-2 checkpoint trained on Python code
model_ckpt = "miguelvictor/python-gpt2-large"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = AutoModel.from_pretrained(model_ckpt)Note: Transformer models like GPT-2 return one embedding vector per token, and we want a single embedding for the entire output.
Define a function to create a single-vector representation for model output using average pooling
- We don’t want to include padding tokens in the average.
def mean_pooling(model_output, attention_mask):
# Extract the token embeddings
token_embeddings = model_output[0]
# Compute the attention mask
input_mask_expanded = (attention_mask
.unsqueeze(-1)
.expand(token_embeddings.size())
.float())
# Sum the embeddings, but ignore masked tokens
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Return the average as a single vector
return sum_embeddings / sum_maskDefine a function to embed sample text
def embed_text(examples):
inputs = tokenizer(examples["text"], padding=True, truncation=True,
max_length=128, return_tensors="pt")
with torch.no_grad():
model_output = model(**inputs)
pooled_embeds = mean_pooling(model_output, inputs["attention_mask"])
return {"embedding": pooled_embeds.cpu().numpy()}Use the end-of-string token as the padding token since GPT-style models don’t have one
tokenizer.pad_token = tokenizer.eos_tokenGet the embeddings for each split
embs_train = ds["train"].map(embed_text, batched=True, batch_size=16)
embs_valid = ds["valid"].map(embed_text, batched=True, batch_size=16)
embs_test = ds["test"].map(embed_text, batched=True, batch_size=16)Dataset.add_faiss_index
- Documentation
- Add a dense index using FAISS for fast retrieval.
- FAISS is a library for efficient similarity search of dense vectors.
import faissCreate a FAISS index using the embeddings for the train split
embs_train.add_faiss_index("embedding") Dataset({
features: ['text', 'labels', 'label_ids', 'embedding'],
num_rows: 223
})datasets.search.IndexableMixin.get_nearest_examples
- Documentation
- Find the nearest examples in the dataset to the query.
Perform a nearest-neighbor lookup
i, k = 0, 3 # Select the first query and 3 nearest neighbors
rn, nl = "\r\n\r\n", "\n" # Used to remove newlines in text for compact display
query = np.array(embs_valid[i]["embedding"], dtype=np.float32)
scores, samples = embs_train.get_nearest_examples("embedding", query, k=k)
print(f"QUERY LABELS: {embs_valid[i]['labels']}")
print(f"QUERY TEXT:\n{embs_valid[i]['text'][:200].replace(rn, nl)} [...]\n")
print("="*50)
print(f"Retrieved documents:")
for score, label, text in zip(scores, samples["labels"], samples["text"]):
print("="*50)
print(f"TEXT:\n{text[:200].replace(rn, nl)} [...]")
print(f"SCORE: {score:.2f}")
print(f"LABELS: {label}") QUERY LABELS: ['new model']
QUERY TEXT:
Implementing efficient self attention in T5
# 🌟 New model addition
My teammates and I (including @ice-americano) would like to use efficient self attention methods such as Linformer, Performer and [...]
==================================================
Retrieved documents:
==================================================
TEXT:
Add Linformer model
# 🌟 New model addition
## Model description
### Linformer: Self-Attention with Linear Complexity
Paper published June 9th on ArXiv: https://arxiv.org/abs/2006.04768
La [...]
SCORE: 54.92
LABELS: ['new model']
==================================================
TEXT:
Add FAVOR+ / Performer attention
# 🌟 FAVOR+ / Performer attention addition
Are there any plans to add this new attention approximation block to Transformers library?
## Model description
The n [...]
SCORE: 57.90
LABELS: ['new model']
==================================================
TEXT:
Implement DeLighT: Very Deep and Light-weight Transformers
# 🌟 New model addition
## Model description
DeLight, that delivers similar or better performance than transformer-based models with sign [...]
SCORE: 60.12
LABELS: ['new model']Note:
- The three retrieved documents all have the same labels as they should.
- The query and the retrieved documents all relate to adding new and efficient transformer models.
Define a function that returns the sample predictions using a label occurrence threshold
def get_sample_preds(sample, m):
return (np.sum(sample["label_ids"], axis=0) >= m).astype(int)datasets.search.IndexableMixin.get_nearest_examples_batch
Define a function to test different k and threshold values for nearest-neighbor search
def find_best_k_m(ds_train, valid_queries, valid_labels, max_k=17):
max_k = min(len(ds_train), max_k)
perf_micro = np.zeros((max_k, max_k))
perf_macro = np.zeros((max_k, max_k))
for k in range(1, max_k):
for m in range(1, k + 1):
_, samples = ds_train.get_nearest_examples_batch("embedding",
valid_queries, k=k)
y_pred = np.array([get_sample_preds(s, m) for s in samples])
clf_report = classification_report(valid_labels, y_pred,
target_names=mlb.classes_, zero_division=0, output_dict=True)
perf_micro[k, m] = clf_report["micro avg"]["f1-score"]
perf_macro[k, m] = clf_report["macro avg"]["f1-score"]
return perf_micro, perf_macroTest different k and threshold values
valid_labels = np.array(embs_valid["label_ids"])
valid_queries = np.array(embs_valid["embedding"], dtype=np.float32)
perf_micro, perf_macro = find_best_k_m(embs_train, valid_queries, valid_labels)Plot the results
fig, (ax0, ax1) = plt.subplots(1, 2, figsize=(10, 3.5), sharey=True)
ax0.imshow(perf_micro)
ax1.imshow(perf_macro)
ax0.set_title("micro scores")
ax0.set_ylabel("k")
ax1.set_title("macro scores")
for ax in [ax0, ax1]:
ax.set_xlim([0.5, 17 - 0.5])
ax.set_ylim([17 - 0.5, 0.5])
ax.set_xlabel("m")
plt.show()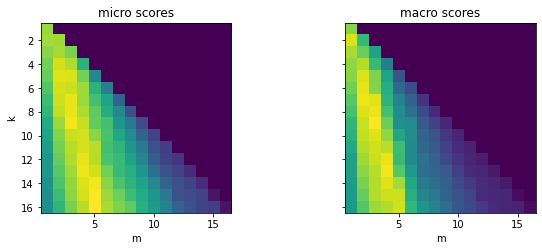
Note:
- Choosing a threshold value \(m\) that is too large or small for a given \(k\) value yields suboptimal results.
- A ratio of approximately \(m/k = 1/3\) achieves the best results.
Find the best k and threshold values
k, m = np.unravel_index(perf_micro.argmax(), perf_micro.shape)
print(f"Best k: {k}, best m: {m}") Best k: 15, best m: 5Note: We get the best performance when we retrieve the 15 nearest neighbors and then assign the labels that occurred at least five times.
Evaluate the embedding lookup performance using different training slices
# Drop the FAISS index
embs_train.drop_index("embedding")
test_labels = np.array(embs_test["label_ids"])
test_queries = np.array(embs_test["embedding"], dtype=np.float32)
for train_slice in train_slices:
# Create a FAISS index from training slice
embs_train_tmp = embs_train.select(train_slice)
embs_train_tmp.add_faiss_index("embedding")
# Get best k, m values with validation set
perf_micro, _ = find_best_k_m(embs_train_tmp, valid_queries, valid_labels)
k, m = np.unravel_index(perf_micro.argmax(), perf_micro.shape)
# Get predictions on test set
_, samples = embs_train_tmp.get_nearest_examples_batch("embedding",
test_queries,
k=int(k))
y_pred = np.array([get_sample_preds(s, m) for s in samples])
# Evaluate predictions
clf_report = classification_report(test_labels, y_pred,
target_names=mlb.classes_, zero_division=0, output_dict=True,)
macro_scores["Embedding"].append(clf_report["macro avg"]["f1-score"])
micro_scores["Embedding"].append(clf_report["micro avg"]["f1-score"])Compare performance to previous methods
plot_metrics(micro_scores, macro_scores, train_samples, "Embedding")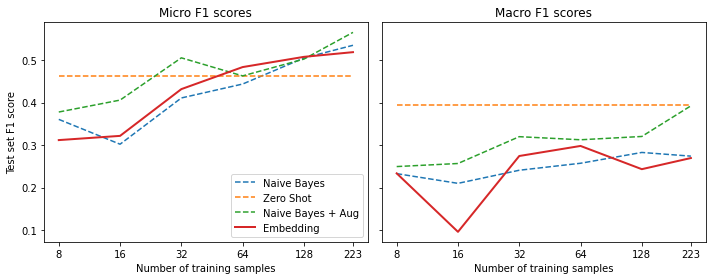
Note:
- The embedding lookup is competitive on the micro F1 scores while only having two “learnable” parameters, k and m, but performs slightly worse on the macro scores.
- The method that works best in practice strongly depends on the domain.
- The zero-shot pipeline might work much better on tasks closer to the pretraining domain.
- The embeddings quality depends on the model and the original training data.
Efficient Similarity Search with FAISS
- We usually speed up text search by creating an inverted index that maps terms to documents.
- An inverted index works just like an index at the end of a book, where each word maps to the pages/documents it occurs in.
- We can quickly find which documents the search terms appear in when performing a query.
- An inverted index works well with discrete objects such as words but does not work with continuous ones like vectors.
- We need to look for similar matches instead of exact matches since each document likely has a unique vector.
- FAISS avoids comparing the query vector to every vector in the database with several tricks.
- FAISS speeds up the comparison process by applying k-means clustering to the dataset, grouping the embeddings by similarity.
- We get a centroid vector for each group, which is the average of all group members.
- We can then search across the k centroids for the one that is most similar to our query and then search within the corresponding group.
- This approach reduces the number of comparisons from n to \(k + \frac{n}{k}\).
- The minimum k value is \(k = \sqrt{n}\).
- FAISS also provides a GPU-enabled version for increased speed and several options to compress vectors with advanced quantization schemes.
- Guidelines to choose an index
Fine-Tuning a Vanilla Transformer
- We can fine-tune a pretrained transformer model when we have labeled data.
- Starting with a pretrained BERT-like model is often a good idea.
- The target corpus should not be too different from the pretraining corpus.
- The Hugging Face hub has many models pretrained on different corpora.
import torch
from transformers import (AutoTokenizer, AutoConfig,
AutoModelForSequenceClassification)Load the pretrained tokenizer for the standard BERT checkpoint
model_ckpt = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)Tokenize the dataset
def tokenize(batch):
return tokenizer(batch["text"], truncation=True, max_length=128)
ds_enc = ds.map(tokenize, batched=True)
ds_enc = ds_enc.remove_columns(['labels', 'text'])Change the label_ids column data type to float for the multilabel loss function
ds_enc.set_format("torch")
ds_enc = ds_enc.map(lambda x: {"label_ids_f": x["label_ids"].to(torch.float)},
remove_columns=["label_ids"])
ds_enc = ds_enc.rename_column("label_ids_f", "label_ids")from transformers import Trainer, TrainingArgumentsKeep the best model based on the micro \(F_{1}\)-score
training_args_fine_tune = TrainingArguments(
output_dir="./results", num_train_epochs=20, learning_rate=3e-5,
lr_scheduler_type='constant', per_device_train_batch_size=4,
per_device_eval_batch_size=32, weight_decay=0.0,
evaluation_strategy="epoch", save_strategy="epoch",logging_strategy="epoch",
load_best_model_at_end=True, metric_for_best_model='micro f1',
save_total_limit=1, log_level='error')from scipy.special import expit as sigmoidDefine a function to compute the \(F_{1}\)-scores
def compute_metrics(pred):
y_true = pred.label_ids
# Normalize the model predictions
y_pred = sigmoid(pred.predictions)
y_pred = (y_pred>0.5).astype(float)
clf_dict = classification_report(y_true, y_pred, target_names=all_labels,
zero_division=0, output_dict=True)
return {"micro f1": clf_dict["micro avg"]["f1-score"],
"macro f1": clf_dict["macro avg"]["f1-score"]}Intitialize a BertConfig for Multi-label classification
config = AutoConfig.from_pretrained(model_ckpt)
config.num_labels = len(all_labels)
config.problem_type = "multi_label_classification"config BertConfig {
"_name_or_path": "bert-base-uncased",
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1",
"2": "LABEL_2",
"3": "LABEL_3",
"4": "LABEL_4",
"5": "LABEL_5",
"6": "LABEL_6",
"7": "LABEL_7",
"8": "LABEL_8"
},
"initializer_range": 0.02,
"intermediate_size": 3072,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1,
"LABEL_2": 2,
"LABEL_3": 3,
"LABEL_4": 4,
"LABEL_5": 5,
"LABEL_6": 6,
"LABEL_7": 7,
"LABEL_8": 8
},
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"problem_type": "multi_label_classification",
"transformers_version": "4.18.0",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 30522
}Train a classifier from scratch for each training slice
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
for train_slice in train_slices:
model = AutoModelForSequenceClassification.from_pretrained(model_ckpt,
config=config).to(device)
trainer = Trainer(
model=model, tokenizer=tokenizer,
args=training_args_fine_tune,
compute_metrics=compute_metrics,
train_dataset=ds_enc["train"].select(train_slice),
eval_dataset=ds_enc["valid"])
old_collator = trainer.data_collator
trainer.data_collator = lambda data: dict(old_collator(data))
trainer.train()
pred = trainer.predict(ds_enc["test"])
metrics = compute_metrics(pred)
macro_scores["Fine-tune (vanilla)"].append(metrics["macro f1"])
micro_scores["Fine-tune (vanilla)"].append(metrics["micro f1"])Compare the results to previous methods
plot_metrics(micro_scores, macro_scores, train_samples, "Fine-tune (vanilla)")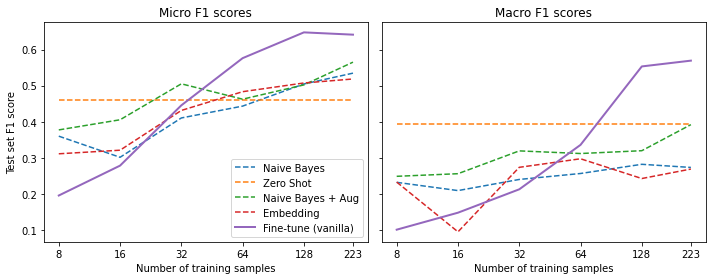
Note: The fine-tuned model is competitive when we have at least 64 training examples.
In-Context and Few-Shot Learning with Prompts
- The GPT-3 paper found that large-language models can effectively learn from examples presented in a prompt.
- The larger the model, the better it is at using in-context examples.
- An alternative to using labeled data is to create examples of the prompts and desired predictions and continue training the language model on those examples.
- ADAPET beats GPT-3 on a wide variety of tasks using this approach.
- Researchers at Hugging Face found that this approach can be more data-efficient than fine-tuning a custom head.
Leveraging Unlabeled Data
- Domain adaptation involves continuing the pretraining process of predicting masked words using unlabeled data from the target domain.
- We can then reuse the adapted model for many use cases.
- Domain adaptation can help boost model performance with unlabeled data and little effort.
Fine-Tuning a Language Model
- We need to mask the
[CLS]and[SEP]tokens from the loss, so we don’t train the model to predict them when doing masked language modeling. - We can get a mask when tokenizing by setting
return_special_tokens_mask=True. - We can use a specialized data collator to prepare the elements in a batch for masked language modeling on the fly.
- The data collator needs to mask tokens in the input sequence and have the target tokens in the outputs.
Define a function to tokenize the text and get the special token mask information
def tokenize(batch):
return tokenizer(batch["text"], truncation=True,
max_length=128, return_special_tokens_mask=True)Retokenize the text
ds_mlm = ds.map(tokenize, batched=True)
ds_mlm = ds_mlm.remove_columns(["labels", "text", "label_ids"])
ds_mlm DatasetDict({
train: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'special_tokens_mask'],
num_rows: 223
})
valid: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'special_tokens_mask'],
num_rows: 106
})
test: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'special_tokens_mask'],
num_rows: 111
})
unsup: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'special_tokens_mask'],
num_rows: 9303
})
})pd.DataFrame(ds_mlm['train']['special_tokens_mask'][0]).T.style.hide(axis='columns').hide(axis='rows')| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
pd.DataFrame(tokenizer.convert_ids_to_tokens(ds_mlm['train']['input_ids'][0])).T.style.hide(axis='columns').hide(axis='rows')| [CLS] | add | new | canine | model | # | [UNK] | new | model | addition | # | # | model | description | recently | proposed | a | new | * | * | c | * | * | hara | ##cter | * | * | a | * | * | rc | ##hit | ##ect | ##ure | with | * | * | n | * | * | o | token | ##ization | * | * | i | * | * | n | * | * | n | * | * | eu | ##ral | * | * | e | * | * | nc | ##oder | ##s | architecture | ( | canine | ) | . | not | only | the | title | is | exciting | : |
|
pipeline | ##d | nl | ##p | systems | have | largely | been | superseded | by | end | - | to | - | end | neural | modeling | , | yet | nearly | all | commonly | - | used | models | still | require | an | explicit | token | ##ization | step | . | while | recent | token | ##ization | approaches | based | on | data | - | derived | sub | ##word | lexi | ##con | ##s | are | [SEP] |
from transformers import DataCollatorForLanguageModeling, set_seedtransformers.data.data_collator.DataCollatorForLanguageModeling
- Documentation
- Create a data collator for language modeling.
Initialize the data collator
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer,
mlm_probability=0.15)Reset random seed
set_seed(3)Test the data collator
# Switch the return formats of the tokenizer and data collator to NumPy
data_collator.return_tensors = "np"
inputs = tokenizer("Transformers are awesome!", return_tensors="np")
outputs = data_collator([{"input_ids": inputs["input_ids"][0]}])
pd.DataFrame({
"Original tokens": tokenizer.convert_ids_to_tokens(inputs["input_ids"][0]),
"Masked tokens": tokenizer.convert_ids_to_tokens(outputs["input_ids"][0]),
"Original input_ids": inputs["input_ids"][0],
"Masked input_ids": outputs["input_ids"][0],
"Labels": outputs["labels"][0]}).T| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| Original tokens | [CLS] | transformers | are | awesome | ! | [SEP] |
| Masked tokens | [CLS] | transformers | are | awesome | [MASK] | [SEP] |
| Original input_ids | 101 | 19081 | 2024 | 12476 | 999 | 102 |
| Masked input_ids | 101 | 19081 | 2024 | 12476 | 103 | 102 |
| Labels | -100 | -100 | -100 | -100 | 999 | -100 |
Switch the return formats of the data collator to PyTorch
data_collator.return_tensors = "pt"from transformers import AutoModelForMaskedLMInitialize the training arguments
training_args = TrainingArguments(
output_dir = f"{model_ckpt}-issues-128", per_device_train_batch_size=32,
logging_strategy="epoch", evaluation_strategy="epoch", save_strategy="no",
num_train_epochs=16, push_to_hub=True, log_level="error", report_to="none", fp16=True)Initialize the Trainer
trainer = Trainer(
model=AutoModelForMaskedLM.from_pretrained("bert-base-uncased").to(device),
tokenizer=tokenizer, args=training_args, data_collator=data_collator,
train_dataset=ds_mlm["unsup"], eval_dataset=ds_mlm["train"])Train the model
trainer.train() TrainOutput(global_step=4656, training_loss=1.2827145487991805, metrics={'train_runtime': 561.7109, 'train_samples_per_second': 264.99, 'train_steps_per_second': 8.289, 'train_loss': 1.2827145487991805, 'epoch': 16.0})Push the trained model to Hugging Face Hub
trainer.push_to_hub("Training complete!") 'https://huggingface.co/cj-mills/bert-base-uncased-issues-128/commit/c7ba31377378cb7fb9412e9524aaf76eed6956b7'Inspect the training and validation losses from the training session
df_log = pd.DataFrame(trainer.state.log_history)
# Drop missing values
(df_log.dropna(subset=["eval_loss"]).reset_index()["eval_loss"]
.plot(label="Validation"))
df_log.dropna(subset=["loss"]).reset_index()["loss"].plot(label="Train")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend(loc="upper right")
plt.show()
Note: Both the training and validation loss decreased significantly.
Free unoccupied cached memory
torch.cuda.empty_cache()Fine-Tuning a Classifier
Initialize a BertConfig for multi-label classification with the custom checkpoint
model_ckpt = "bert-base-uncased"
model_ckpt = f'{model_ckpt}-issues-128'
config = AutoConfig.from_pretrained(model_ckpt)
config.num_labels = len(all_labels)
config.problem_type = "multi_label_classification"
config BertConfig {
"_name_or_path": "bert-base-uncased-issues-128",
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1",
"2": "LABEL_2",
"3": "LABEL_3",
"4": "LABEL_4",
"5": "LABEL_5",
"6": "LABEL_6",
"7": "LABEL_7",
"8": "LABEL_8"
},
"initializer_range": 0.02,
"intermediate_size": 3072,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1,
"LABEL_2": 2,
"LABEL_3": 3,
"LABEL_4": 4,
"LABEL_5": 5,
"LABEL_6": 6,
"LABEL_7": 7,
"LABEL_8": 8
},
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"problem_type": "multi_label_classification",
"torch_dtype": "float32",
"transformers_version": "4.18.0",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 30522
}Fine-tune the classifier on each training slice
for train_slice in train_slices:
model = AutoModelForSequenceClassification.from_pretrained(model_ckpt,
config=config).to(device)
trainer = Trainer(
model=model,
tokenizer=tokenizer,
args=training_args_fine_tune,
compute_metrics=compute_metrics,
train_dataset=ds_enc["train"].select(train_slice),
eval_dataset=ds_enc["valid"],
)
trainer.train()
pred = trainer.predict(ds_enc['test'])
metrics = compute_metrics(pred)
# DA refers to domain adaptation
macro_scores['Fine-tune (DA)'].append(metrics['macro f1'])
micro_scores['Fine-tune (DA)'].append(metrics['micro f1'])plot_metrics(micro_scores, macro_scores, train_samples, "Fine-tune (DA)")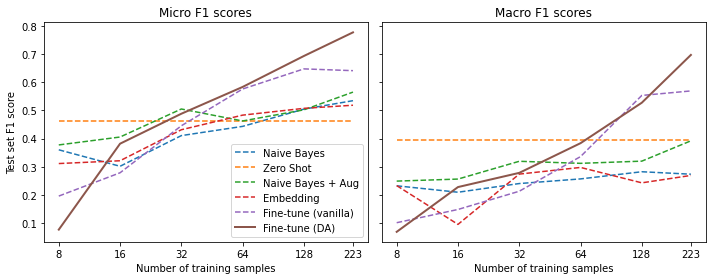
Note: The fine-tuned classifier performs better than the vanilla BERT, especially in the low-data domain.
Advanced Methods
Unsupervised data augmentation
- Unsupervised data augmentation (UDA) works off the idea that a model’s predictions should be consistent for an unlabeled example and a slightly distorted one.
- We can introduce distortions using standard data augmentation strategies.
- We enforce consistency by minimizing the KL divergence between the predictions of the original and distorted examples.
- We incorporate the consistency requirement by augmenting the cross-entropy loss with an additional term from the unlabeled examples.
- The model trains on the labeled data with the standard supervised approach, but we constrain the model to make consistent predictions on the unlabeled data.
- BERT models trained with UDA on a handful of labeled examples get similar performance to models trained on thousands of examples.
- UDA requires a data augmentation pipeline to generate distorted examples.
- Training takes much longer since it requires multiple forward passes to generate the predicted distributions on the unlabeled and augmented examples.
Uncertainty-aware self-training
- Uncertainty-aware self-training (UST) involves training a teacher model on labeled data and using that model to create pseudo-labels for unlabeled data.
- A student model then trains on the pseudo-labeled data.
- We get an uncertainty measure of the student model’s predictions by feeding it the same input several times with dropout turned on.
- The variance of the predictions gives a proxy for the certainty of the model on a specific sample.
- We then sample the pseudo-labels using Bayesian Active Learning by Disagreement (BALD).
- The teacher continuously gets better at creating pseudo-labels, improving the student’s performance.
- UST gets within a few percentages of models trained on datasets with thousands of labeled samples and beats UDA on several datasets.
- Uncertainty-aware Self-training for Text Classification with Few Labels
Conclusion
- Set up an evaluation pipeline to test different approaches for dealing with little to no labeled data.
- Build a validation and test set early on.
- There are tradeoffs between more complex approaches like UDA and UST and getting more data.
- It might make more sense to create a small high-quality dataset rather than engineering a very complex method to compensate for the lack of data.
- Annotating a few hundred examples usually takes a couple of hours to a few days.
- There are many annotation tools available to speed up labeling new data.
References
Previous: Notes on Transformers Book Ch. 8
Next: Notes on Transformers Book Ch. 10
I’m Christian Mills, an Applied AI Consultant and Educator.
Whether I’m writing an in-depth tutorial or sharing detailed notes, my goal is the same: to bring clarity to complex topics and find practical, valuable insights.
If you need a strategic partner who brings this level of depth and systematic thinking to your AI project, I’m here to help. Let’s talk about de-risking your roadmap and building a real-world solution.
Start the conversation with my Quick AI Project Assessment or learn more about my approach.