Conference Talk 3: Prompt Engineering Workshop
- Mastering LLMs Course Notes: My notes from the course Mastering LLMs: A Conference For Developers & Data Scientists by Hamel Husain and Dan Becker.
- What is a Large Language Model?
- Prompt Crafting
- LLMs are Dumb Mechanical Humans
- Building LLM Applications
- Creating the Prompt
- The Introduction of Chat
- The Introduction of Tools
- Building LLM Applications - Continued
- Creating the Prompt: Copilot Chat
- Tips for Defining Tools
- Q&A Session
What is a Language Model?
- Language Model (LM): An AI system trained on vast text data to understand and generate human-like text. Its primary function is predicting the next word in a sequence.
- Large Language Model (LLM): A significantly larger and more complex LM, showcasing enhanced capabilities in understanding and generating human language.
What is a Large Language Model?
Evolution of LLMs:
- Recurrent Neural Networks (RNNs): Initial models with limitations in handling long sequences due to the bottleneck between encoder and decoder.
- Attention Mechanism: Introduced to focus on relevant parts of the input sequence, addressing the limitations of RNNs.
- Transformer Architecture: Replaced RNNs by focusing entirely on attention, leading to significant improvements in performance and efficiency.
- Paper: Attention Is All You Need
- BERT and GPT:
- BERT (Bidirectional Encoder Representations from Transformers): Utilizes the encoder part of the transformer, excelling in tasks like understanding the context of words in a sentence.
- GPT (Generative Pre-trained Transformer): Utilizes the decoder part of the transformer, specializing in generating coherent and contextually relevant text.
Capabilities and Concerns:
- GPT-2 exhibited impressive unsupervised capabilities across various tasks, including translation, summarization, and question answering.
- The power of LLMs raises concerns about potential misuse, as they can be manipulated to generate misleading or harmful content.
Prompt Crafting
- Prompt: Instructions or context provided to an LLM to guide its text generation process. Effective prompt crafting is crucial for achieving desired outputs.
Technique #1: Few-Shot Prompting
- Concept: Providing the LLM with a few examples of the desired input-output pattern, enabling it to understand and generalize to new, similar tasks.
- NoteExample: Translating English to Spanish
Examples to set the pattern:
> How are you doing today? < ¿Cómo estás hoy? > My name is John. < Mi nombre es John.The actual task:
> Can I have fries with that? < ¿Puedo tener papas fritas con eso?
Technique #2: Chain-of-Thought Reasoning
- Concept: Improving LLM’s reasoning abilities by prompting them to generate a step-by-step thought process leading to the solution, especially useful for tasks involving logic and reasoning.
- NoteExample: Guiding the model to break down the problem into smaller, logical steps
# Trainging Example Q: Jim is twice as old as Steve. Jim is 12 years how old is Steve. A: In equation form: 12=2*a where a is Steve's age. Dividing both sides by 2 we see that a=6. Steve is 6 years old. # Test Question Q: It takes one baker an hour to make a cake. How long does it take 3 bakers to make 3 cakes? # Answer with Reasoning A: The amount of time it takes to bake a cake is the same regardless of how many cakes are made and how many people work on them. Therefore the answer is still 1 hour.
Thinking Step-by-Step
- Simplified Approach: A variation of chain-of-thought reasoning where instead of providing multiple examples, the prompt directly instructs the model to “think step-by-step.”
- NoteExample:
Q: It takes one baker an hour to make a cake. How long does it take 3 bakers to make 3 cakes? # Prime the model by starting it's answer with "Let's think step-by-step." A: Let's think step-by-step. The amount of time it takes to bake a cake is the same regardless of how many cakes are made and how many people work on them. Therefore the answer is still 1 hour. - Advantages:
- Reduces the need for crafting numerous examples.
- Avoids potential bias from examples bleeding into the answer.
- Improves prompt efficiency by using shorter instructions.
Technique #3: Document Mimicry
- Concept: Leveraging the LLM’s knowledge of specific document structures and formats to guide its output towards a desired style and content.
- Example: Crafting a prompt in the format of a customer support transcript, using headings, roles (Customer, Support Assistant), and Markdown formatting to elicit a response mimicking a helpful support interaction.
- NoteExample:
# IT Support Assistant The following is a transcript between an award winning IT support rep and a customer. ## Customer: My cable is out! And I'm going to miss the Superbowl! ## Support Assistant: Let's figure out how to diagnose your problem…- Document type: transcript
- Tells a story to condition a particular response
- Uses Markdown to establish structure
LLMs are Dumb Mechanical Humans
- Use Familiar Language and Constructs: LLMs perform better with language and structures commonly found in their training data.
- Avoid Overloading with Context: While providing context is essential, too much information can distract the model and hinder its performance.
- Provide Necessary Information: LLMs are not psychic; they rely on the prompt for information not present in their training data.
- Ensure Prompt Clarity: If the prompt is confusing for a human, it will likely be confusing for the LLM as well.
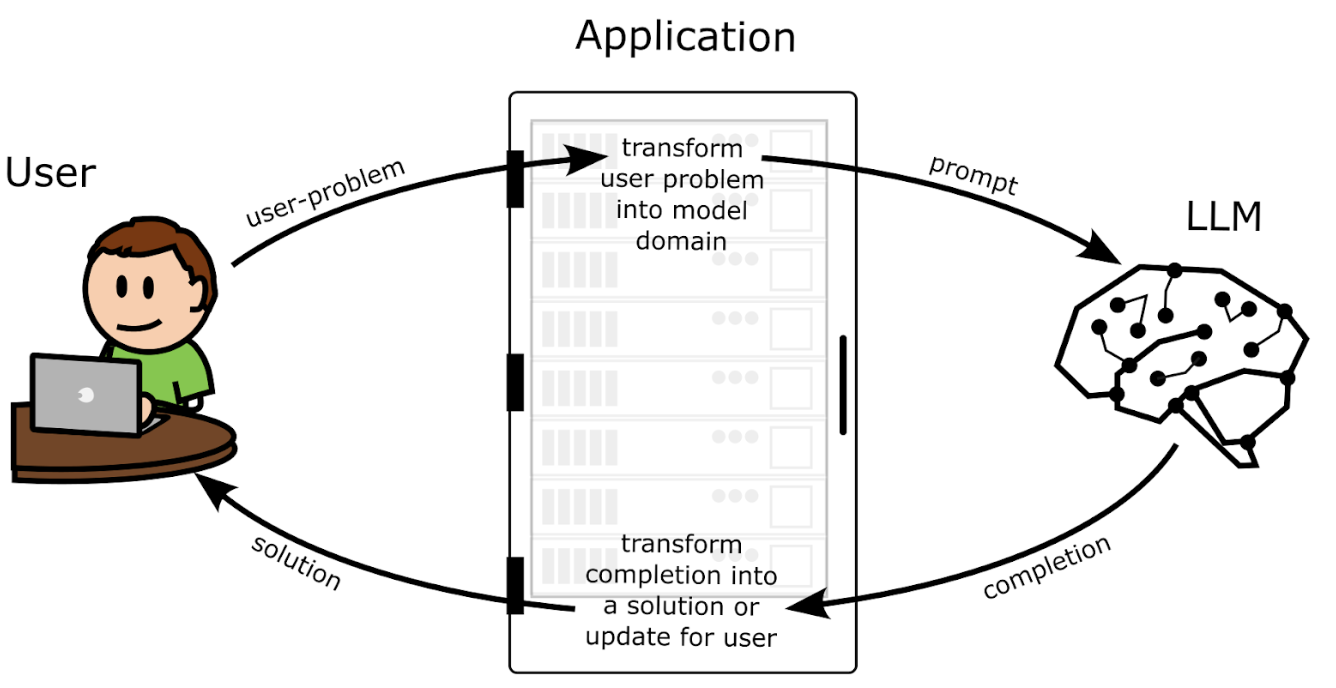
Building LLM Applications
- LLMs as Transformation Layers: LLM applications act as intermediaries between the user’s problem domain and the LLM’s text-based domain.
- Process:
- User Request: The user interacts with the application, providing a request or input.
- Transformation to LLM Space: The application converts the user’s request into a text-based prompt understandable by the LLM.
- LLM Processing: The LLM processes the prompt and generates a text output.
- Transformation to User Space: The application converts the LLM’s text output into a format actionable and understandable by the user.
Creating the Prompt
- Prompt Creation for Completion Models:
- Context Collection: Gather relevant information from sources like the current document, open tabs, and relevant symbols.
- Context Ranking: Prioritize the collected context based on its importance and relevance to the task.
- Context Trimming: Condense or eliminate less crucial context to fit within the LLM’s input limits.
- Document Assembly: Structure the prompt in a clear and organized manner, mimicking relevant document formats if applicable.
Copilot Code Completion
- Context Collection:
- Current document, open tabs, symbols used, file path.
- Context Ranking:
- File path (most important)
- Current document
- Neighboring tabs
- Symbols (least important)
- Context Trimming: Prioritizes keeping the file path, current document, and relevant snippets from open tabs.
- Document Assembly: Structures the prompt with file path at the top, followed by snippets from open tabs, and finally, the current document up to the cursor position.
- NoteExample:
- 1
- file path
- 2
- snippet from open tab
- 3
- current document
- 4
- cursor
The Introduction of Chat
- Shift Towards Conversational Interfaces: Chat interfaces have become a popular paradigm for LLM applications.
- Blog Post: Introducing ChatGPT
- ChatML: A specialized syntax used to represent chat conversations, with roles like “user” and “assistant” and special tokens to delineate messages.
- NoteAPI
messages = [{ "role": "system" "content": "You are an award winning support staff representative that helps customers." }, {"role": "user", "content":"My cable is out! And I'm going to miss the Superbowl!" } ] - NoteDocument
<|im_start|> system You are an award winning IT support rep. Help the user with their request.<|im_stop|> <|im_start|> user My cable is out! And I'm going to miss the Superbowl!<|im_stop|> <|im_start|> assistant Let's figure out how to diagnose your problem… - Benefits of Chat-Based Interfaces:
- Natural Interaction: Mimics human conversation, providing a more intuitive user experience.
- System Messages: Allow developers to control the assistant’s behavior and personality.
- Enhanced Safety: Chat-based models are often fine-tuned to avoid generating harmful or inappropriate content.
- Reduced Prompt Injection Risk: Special tokens in ChatML make it difficult for users to manipulate the assistant’s behavior through malicious prompts.
The Introduction of Tools
Extending LLM Capabilities: Tools enable LLMs to interact with external systems and data, expanding their functionality beyond text generation.
- Blog Post: Function calling and other API updates
Function Calling: Allows developers to define functions that the LLM can call to access external APIs or perform specific actions.
- NoteExample: Get Weather Function
{ "type": "function", "function": { "name": "get_weather", "description": "Get the weather", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city and state", }, "unit": { "type": "string", "description": "degrees Fahrenheit or Celsius", "enum": ["celsius", "fahrenheit"] }, }, "required": ["location"], }, }, } - NoteInput:
{ "role": "user", "content": "What's the weather like in Miami?" } - NoteFunction Call:
{ "role": "assistant", "function": { "name": "get_weather", "arguments": '{"location": "Miami, FL"}' } } - NoteReal API Request:
curl http://weathernow.com/miami/FL?deg=f # Response {"temp": 78} - NoteFunction Response:
{ "role": "tool", "name": "get_weather", "content": "78ºF" } - NoteAssistant Response:
{ "role": "assistant", "content": "It's a balmy 78ºF" }
Benefits of Tool Usage:
- Real-World Interaction: LLMs can now access and manipulate information in the real world through APIs.
- Flexibility in Response: Models can choose to respond to user requests by either calling functions or providing text-based answers.
- Potential for Parallel Processing: LLMs are being developed to execute multiple function calls concurrently, improving efficiency.
Building LLM Applications - Continued
- Enhanced Application Architecture: With the introduction of chat and tool calling, the architecture of LLM applications becomes more sophisticated.
- Bag of Tools Agent:
- Prompt Crafting: Incorporates previous messages, context, tool definitions, and the user’s current request.
- Bifurcated Processing: The LLM can either call a function based on the prompt or generate a text response directly.
- Iterative Interaction: The application handles function calls, integrates results back into the prompt, and facilitates ongoing conversation.
- NoteExample: Temperature Control
user: make it 2 degrees warmer in here assistant: getTemp() function: 70ºF assistant: setTemp(72) function: success assistant: Done! user: actually… put it back assistant: setTemp(70) function: success assistant: Done again, you fickle pickle!
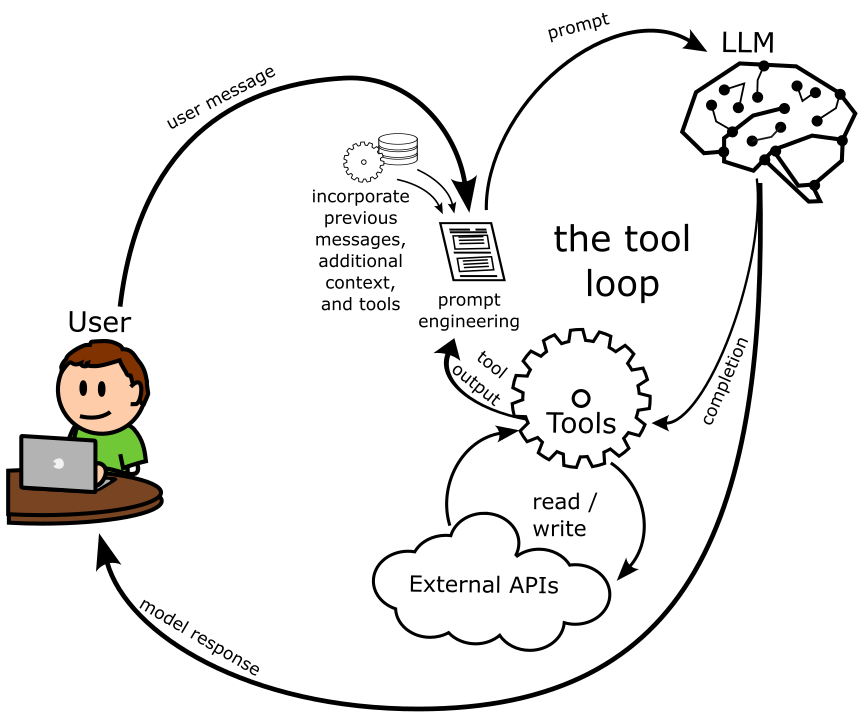
Creating the Prompt: Copilot Chat
- Context Collection:
- Open files, highlighted code snippets, clipboard contents, relevant GitHub issues, previous messages in the conversation.
- Context Ranking:
- System message (essential for safety and behavior control)
- Function definitions (if applicable)
- User’s most recent message
- Function call history and evaluations
- References associated with messages
- Historic messages (least important)
- Context Trimming: Prioritizes keeping essential elements and trimming less crucial information like historic messages or function definitions if space is limited.
- Fallback Mechanisms: If the prompt becomes too large, the application should have strategies to handle the situation gracefully, such as prioritizing essential elements or informing the user about limitations.
Tips for Defining Tools
- Quantity:
- Don’t have “too many” tools
- Look for evidence of collisions
- Names:
- Use simple and clear names
- Consider using typeScript format
- Arguments:
- Keep arguments simple and few
- Don’t copy/paste your API
- Nest arguments don’t retain descriptions
- Can use enum and default, but not minimum, maximum
- Keep arguments simple and few
- Descriptions:
- Keep them short and consider what the model knows
- Probably understands public documentation.
- Doesn’t know about internal company acronyms.
- Keep them short and consider what the model knows
- Output: Don’t include extra “just-in-case” content
- Errors: when reasonable, send errors to model (validation errors)
Q&A Session
Copilot and Code Analysis
- Question: Can Copilot analyze codebases beyond open tabs to provide more context-aware suggestions?
- Answer: While not currently available, Copilot’s code analysis capabilities are under active development and expected to improve.
- Related Ideas: Sourcegraph was mentioned as a company with interesting code analysis tools.
Few-Shot Prompting
- Question: How many examples are ideal for few-shot prompting, and where should they be placed?
- Answer: There’s no single answer, as it depends on the task and model. Experimentation is key.
- Best Practices:
- Log Probabilities: Analyze the log probabilities of predicted tokens to gauge if the model is grasping the pattern from the examples. High and leveling off probabilities suggest sufficient examples.
- Placement: For completion models, examples go directly in the prompt. For chat assistants, consider the message flow and potentially use fake user messages to position examples effectively.
Hyperparameter Tuning
- Question: What hyperparameters should be adjusted when iterating on prompts, and how do they impact results?
- Answer: Temperature and the number of completions are key parameters to experiment with.
- Parameter Explanations:
- Temperature: Controls the randomness of the model’s output.
- 0 = deterministic, less creative
- 0.7 = a good balance for creativity (used in Copilot Chat)
- 1 = follows the natural probability distribution
- Higher values increase randomness, potentially leading to gibberish.
- Number of Completions (n): Requesting multiple completions (e.g., n=100) can be useful for evaluation or generating a wider range of outputs. Set a reasonably high temperature to avoid repetitive results.
- Temperature: Controls the randomness of the model’s output.
Structuring LLM Outputs
- Question: How can you guide an LLM to summarize information into a structured format like JSON?
- Answer:
- Function Calling: Define functions within the prompt that specify the desired output structure (e.g., a function to extract restaurant details). LLMs are trained to understand and utilize JSON-like structures within function definitions.
- Simplified APIs: Avoid overly complex nested structures in function definitions. Break down tasks into smaller, more manageable steps if needed.
Challenges with Complex Function Arguments
- Observation: Passing highly nested data structures as function arguments can be difficult for both humans and LLMs to interpret.
- Recommendations:
- Simplicity: Strive for clear and concise function arguments.
- Evaluation: Thoroughly test and evaluate how well the LLM handles complex structures.
- Iterative Refinement: Consider simplifying APIs or data structures if the LLM struggles with complexity.
Understanding OpenAI’s Function Calling Mechanism
- Question: How does OpenAI handle function calling internally?
- Answer: OpenAI transforms function definitions into a TypeScript-like format internally, adding comments for descriptions and argument details. However, nested structures may lose some type information during this process.
- Key Takeaway: While LLMs can handle some complexity, being mindful of the underlying representation can help in designing more effective function calls.
Improving Code Generation
- Question: How to improve the quality of code generated by LLMs, especially in tools like Copilot?
- Answer:
- Clear Comments: Provide explicit instructions within code comments to guide the model’s completions (e.g., describe the intended logic or syntax).
- Code Style: LLMs tend to mimic the style of the provided code. Writing clean and well-structured code can lead to better completions.
Prompt Engineering Tools
- Question: What are your thoughts on tools like DSPy for automated prompting?
- GitHub Repository: dspy
- Answer:
- Value of Direct Interaction: Starting with direct interaction with LLMs (without intermediary tools) is crucial for building intuition and understanding.
- Potential Benefits of Tools: Tools like DSPy can automate tasks like finding optimal few-shot examples, potentially saving time and effort.
- Trade-offs: Abstraction can sometimes obscure the underlying mechanisms and limit fine-grained control.
Advanced Prompting Techniques
- Question: Beyond chain-of-thought prompting, what other techniques are worth exploring?
- Answer:
- ReAct (Reason + Act): Involves defining a set of “fake” functions within the prompt, allowing the model to reason about which actions to take to solve a problem.
- Reflexion: Focuses on evaluating and iteratively improving the model’s output. For example, running generated code through tests and feeding error messages back into the prompt for correction.
I’m Christian Mills, an Applied AI Consultant and Educator.
Whether I’m writing an in-depth tutorial or sharing detailed notes, my goal is the same: to bring clarity to complex topics and find practical, valuable insights.
If you need a strategic partner who brings this level of depth and systematic thinking to your AI project, I’m here to help. Let’s talk about de-risking your roadmap and building a real-world solution.
Start the conversation with my Quick AI Project Assessment or learn more about my approach.