Conference Talk 1: Ten Commandments to Deploy Fine-Tuned Models in Production
- Mastering LLMs Course Notes: My notes from the course Mastering LLMs: A Conference For Developers & Data Scientists by Hamel Husain and Dan Becker.
- 1: Thou Shalt Not Fine-Tune
- 2: Thou Shalt Write a Freaking Prompt
- 3: Thou Shalt Review Thy Freaking Data
- 4: Thou Shalt Use Thy Actual Freaking Data
- 5: Thou Shalt Reserve a Test Set
- 6: Thou Shalt Choose an Appropriate Model
- 7: Thou Shalt Write Fast Evals
- 8: Also, Thou Shalt Write Slow Evals
- 9: Thou Shalt Not Fire and Forget
- 10: Thou Shalt Not Take the Commandments Too Seriously
- Q&A Highlights
Thou Shalt Not Fine-Tune
- Start with Prompting: Focus on crafting effective prompts and leverage techniques like few-shot learning before considering fine-tuning.
- Reasons to Fine-Tune: Only fine-tune if prompting cannot achieve desired outcomes due to:
- Quality: Prompting alone cannot meet the required performance standards.
- Latency: Fine-tuning allows the use of smaller, faster models for real-time applications.
- Cost: Fine-tuning enables the use of smaller, more cost-effective models at scale.
Thou Shalt Write a Freaking Prompt
- Establish a Baseline: A well-crafted prompt provides a performance baseline for comparison with fine-tuned models.
- Assess Task Feasibility: Trying to solve the problem with prompting reveals whether the task is achievable with the available data and model capabilities.
- Check Data Quality:
- Successful prompting suggests your data has enough signal for effective model learning.
- Failed prompting often indicates data issues like inconsistencies or insufficient information.
Example: Logistics Company & Item Valuation
- Goal: Predict item values from descriptions.
- Assumption: That descriptions contained enough information for a model to infer value.
- Outcome: Prompting revealed that the descriptions lacked sufficient detail.
Heuristic: Prompting Success Predicts Fine-tuning Success
- If you can achieve reasonable performance with a well-crafted prompt, there’s a high probability (90%+) that fine-tuning will yield further improvements in latency, quality, or cost.
- If prompting proves ineffective, successfully fine-tuning the model becomes less certain and significantly more challenging.
Recommended Workflow: Prototype to Production
- Prototype with GPT-4: During the initial stages, focus on rapid iteration and validation of your application’s core concept. Utilize GPT-4 and prompting to experiment and refine your approach.
- Transition to Fine-tuning: Once you have a working prototype that demonstrates value and scalability, consider incorporating fine-tuning to optimize performance further.
Thou Shalt Review Thy Freaking Data
Importance of Data Review
- Evaluate Model Performance: See how well the prompt guides the model to generate desired outputs in real-world scenarios.
- Understand User Behavior: Gain insights into how users interact with the prompt and the types of inputs they provide. This is crucial for:
- Refining Assumptions: Avoid making inaccurate assumptions about user needs and use cases.
- Improving Prompt Design: Tailor the prompt to better align with actual usage patterns.
- Developing Targeted Tests: Create more effective tests based on real-world input data.
How to Review Data
- Utilize Existing UI: If your system has a user interface (e.g., chat interface, classification system), leverage it to observe input-output pairs in context.
- Employ Specialized Tools: If a dedicated UI is unavailable, utilize tools like OpenPipe to visualize and analyze input and output data in a structured format.
What to Look For
- Input Distribution: Pay close attention to the variety, complexity, and common patterns within user inputs.
- Output Quality: Assess the relevance, accuracy, and overall quality of model outputs in response to real-world inputs.
Thou Shalt Use Thy Actual Freaking Data
The Importance of Using Your Actual Data
- Don’t exclude “bad” data:
- Removing data points where the base model performs poorly can lead to a model that excels in a limited domain while failing in real-world scenarios.
- The “bad” data likely represents real-world inputs your model needs to handle.
- Removing data points where the base model performs poorly can lead to a model that excels in a limited domain while failing in real-world scenarios.
- Example: If your model struggles with a specific class of data and you exclude it, the fine-tuned model will likely repeat the mistake in production.
Addressing Poor Performance
- Diagnose the issue: Instead of removing “bad” data, analyze why the model struggles.
- Is there a pattern in the input space where it fails?
- Can you improve the instructions to guide the model better?
- Solutions:
- Manually relabel data: Use a relabeling UI to correct outputs.
- Refine instructions: Experiment with different prompts and instructions to improve performance.
When Imperfect Data Can Be Useful
- Generalization and regularization:
- Large LLMs are surprisingly good at generalizing from imperfect data.
- The training process itself acts as a form of regularization, allowing the model to learn from both correct and incorrect examples.
- Training on model outputs:
- Fine-tuning on the outputs of a larger model (e.g., GPT-4) can lead to a smaller model that outperforms the original due to this regularization effect.
- The smaller model learns from the larger model’s successes and avoids repeating its occasional errors.
- Fine-tuning on the outputs of a larger model (e.g., GPT-4) can lead to a smaller model that outperforms the original due to this regularization effect.
- Caveat: This applies mainly to larger LLMs (4B+ parameters) where errors are relatively random. If there’s a consistent pattern of errors, address it directly.
Thou Shalt Reserve a Test Set
Importance of a Test Set: A dedicated test set, separate from the training data, is essential to evaluate the true performance of a fine-tuned language model.
Common Pitfalls:
- Non-representative Test Sets: Test sets with hand-picked examples, often based on perceived poor performance or customer complaints, are often not representative of the overall input data and can lead to misleading results.
- Exclusively Using Non-Random Test Sets: Relying solely on a set a specific corner cases can give a false sense of performance as the model might not generalize well to unseen data.
Recommendations:
- Create a Randomly Sampled Test Set: Reserve 5-10% of your data randomly as a test set. This ensures that the model’s performance is evaluated on data representative of the overall distribution.
- Maintain Separate Test Sets: Use both a randomly sampled test set for general performance evaluation and a separate set for targeted testing of specific corner cases or challenging examples.
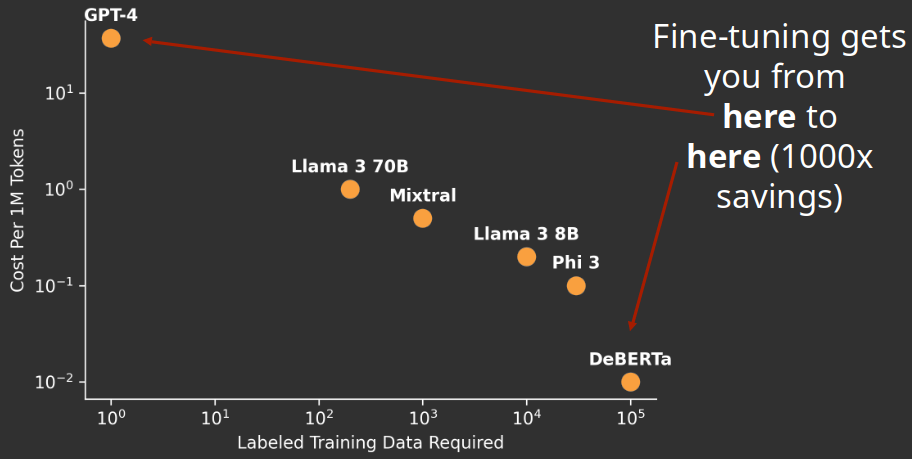
Thou Shalt Choose an Appropriate Model
Choosing a Model
Experimentation is Key: The cost of fine-tuning runs is relatively low, allowing for trying different models with your data.
Dataset Size Matters:
- Small Datasets (Dozens): Larger models like Llama2 70B can often match GPT-4’s performance.
- Medium Datasets (Thousands): Llama2 7B-8B or Mistral 7B offer a good balance.
- Task Dependency: Some tasks may never reach GPT-4’s level regardless of training data.
Sweet Spot: 7B-8B parameter models are recommended for most production use cases due to:
Sufficient Performance: Achievable with around 1,000-5,000 training examples.
Cost Savings: Significantly cheaper inference costs compared to GPT-4 (around 15-20 cents per million tokens vs. GPT-4’s much higher cost).
Thou Shalt Write Fast Evals
Fast Evaluations:
- Can be integrated into the training loop or prompt engineering workflow.
- Quick and inexpensive to run.
- Provide immediate feedback on model performance.
LLM as Judge
- Default Recommendation: Use an LLM (e.g., GPT-4) to evaluate the quality of outputs.
- Method: Present the LLM judge with the input task and outputs from different models. Ask the judge to compare and rate the quality.
- Considerations:
- Randomization: Randomize the order of presented outputs to avoid bias towards the first option.
- Self-Preference: Be aware that LLMs tend to prefer their own outputs if evaluated on themselves.
- Tools and Libraries: Utilize existing libraries (some suggested on OpenPipe) that streamline this process.
Benefits of Fast Evaluations
- Rapid Iteration: Quickly test changes to prompts, fine-tuning, etc., and get immediate feedback.
- Direction Confirmation: Ensure that development efforts are moving in the right direction.
- Faster Feedback Cycle: Avoid the long delays associated with slower, production-level evaluations.
Also, Thou Shalt Write Slow Evals
The Need for Slow Evaluations
- Fast vs. Slow Evaluations: Fast evaluations are quick checks of model performance in isolation, while slow evaluations assess the model’s impact in a real-world setting.
- Importance of Real-World Impact: Even if a model performs well in isolation, other system interactions or deployment factors (like quantization) can lead to unexpected results. Slow evaluations capture this.
- Outcome-Driven Evaluation: Design evaluations based on the desired business or product outcome. For example, if building a customer support chatbot, measure customer satisfaction with problem resolution.
Examples from OpenAI’s ChatGPT
- User Engagement Metrics: OpenAI tracks metrics like how often users regenerate responses or give “thumbs down” as indicators of model performance.
- Side-by-Side Comparisons: While less frequent, OpenAI sometimes presents users with two responses side-by-side, allowing them to choose the better one. This provides direct comparative feedback.
Thou Shalt Not Fire and Forget
Continuous Evaluation is Crucial
- After deploying a fine-tuned model, it is essential to continuously evaluate its performance using objective metrics and real-world data. This helps detect any degradation in accuracy.
Data Drift
- The world is constantly changing, and so is the data that models encounter.
- Data drift occurs when the input data starts to differ from the data the model was originally trained on, leading to decreased performance.
Real-World Example
- Problem: A customer using a fine-tuned model for extracting data from call logs experienced a decline in accuracy.
- The training data only contained examples from 2023, leading the model to always use the year 2023 when extracting dates even for calls made in 2024.
- Solution: The problem was solved by retraining the model with a small set of examples from 2024, demonstrating the importance of keeping the training data up-to-date.
Thou Shalt Not Take the Commandments Too Seriously
- The above recommendations are only guidelines, not hard requirements.
- Tailor your approach based on the specific requirements of your project and data.
Q&A Highlights
- Data Quality vs. Effort: While higher-quality data generally leads to better results, strive for a balance between data refinement and the overall time investment.
- When to Fine-Tune: Fine-tuning is more beneficial when the task is highly specific and diverges from the capabilities of a general-purpose chatbot.
- Low-Resource Languages:
- Fine-tuning for low-resource languages can be effective with sufficient data.
- Consider pre-trained multilingual models as a starting point.
- Evaluation During Training:
- Fine-tune on an initial dataset.
- If evaluation results are unsatisfactory, increase the dataset size and re-evaluate.
- Deployment and Inference Optimization:
- Low-Rank Adaptation (LoRA):
- Fine-tunes a smaller set of parameters, resulting in faster training and reduced inference costs.
- Allows for loading multiple LoRA models simultaneously in VLM or TRT LLM, maximizing GPU utilization.
- Serverless Endpoints: Services like OpenPipe, Fireworks, and OctoAI provide cost-effective deployment options by handling infrastructure and utilizing timesharing among users.
- Low-Rank Adaptation (LoRA):
- Reasoning Chains:
- Challenges: Complex reasoning tasks may pose difficulties for fine-tuned models, even if they can be solved by larger models like GPT-4.
- Factors Influencing Success:
- Reproducibility of reasoning patterns.
- Availability of sufficient training data covering diverse scenarios within the reasoning chain.
- Recommendations:
- Log the entire reasoning chain during data collection.
- Ensure data freshness by updating traces if function definitions or other components change.
- Consider generating synthetic data to augment the dataset and cover a wider range of scenarios, especially for complex chains.
- JSON Extraction and Evaluation:
- Tracing: Tracing all LLM calls for JSON extraction is recommended, as storage is relatively inexpensive and should not significantly impact latency in a well-designed system.
- Evaluation with Larger Models: Using a larger model like GPT-4 for evaluating extractions is acceptable. Random sampling can be used to manage costs if necessary.
- Fine-Tuning for Classification with Decoder Models: While encoder models are theoretically advantageous for classification, there’s a lack of readily available, high-quality, open-source encoder models, especially for long context scenarios.
- Relabeling UI Recommendations: Explore tools like Argilla or consider building custom solutions tailored to your specific needs.
- Fine-Tuning Techniques Comparison (LoRa, QLoRa, DoRa): Start with LoRa for its efficiency and regularization benefits. Consider full fine-tuning or DoRa if LoRa’s performance is insufficient.
- Multimodal Scenarios: While production use cases for vision-language models are still emerging, advancements in open-source models are expected to drive adoption.
- Models on the Efficient Frontier: Current techniques may have reached a saturation point for model efficiency in smaller model sizes.
I’m Christian Mills, an Applied AI Consultant and Educator.
Whether I’m writing an in-depth tutorial or sharing detailed notes, my goal is the same: to bring clarity to complex topics and find practical, valuable insights.
If you need a strategic partner who brings this level of depth and systematic thinking to your AI project, I’m here to help. Let’s talk about de-risking your roadmap and building a real-world solution.
Start the conversation with my Quick AI Project Assessment or learn more about my approach.